Author Melchior de Roquefeuil
Category Programming
Tags Java, LLVM, obfuscation, programming, 2019
In this article I describe my two-months summer internship project at Quarkslab: obfuscating Java bytecode using the [Epona] Code Obfuscator. This article explains our approach, its advantages and limitations.
Introduction
Languages like Java, .Net or OCaml are typically compiled to platform independent bytecode before execution. The bytecode is then interpreted and/or compiled to target dependent machine code at runtime. The Java Bytecode is run by the Java Virtual Machine (JVM) and is generated from Java or other languages targeting it, like Scala or the more recent Kotlin language.
A typical Java program bytecode is not specifically optimized, this job is better left to the JVM. Because of this, many powerful free Java bytecode decompilation tools can be found online. This means that it is really easy to decompile any non obfuscated Java program. Lots of free and commercial tools also exist to obfuscate Java code, in order to make this decompilation process harder for reverse engineers.
[Epona] provides a C/C++ compiler with opt-in obfuscation features developed by Quarkslab, mainly targeting C and C++. One of our wish is to use the Epona obfuscator on Java, allowing us to implement, maintain, debug and improve the obfuscation techniques without doubling the necessary work.
As code obfuscations in Epona are implemented as transformations over the [LLVM] Intermediate Representation [1], the goal of this internship was to try whether going from Java bytecode to LLVM IR back-and-forth was a viable solution or not, and to identify problems that could arise.
We will start this blog post by exploring existing solutions. We will then explain how we are going from Java bytecode to LLVM IR and back to Java bytecode. Finally, we will take a look at some optimized and obfuscated examples.
Existing solutions
Various projects exist around the idea of using both Java and LLVM, mainly falling into two categories:
compiling Java to native code thanks to LLVM
running LLVM IR within a JVM
In this section, we describe these projects and why they don't completely fit with our goal.
Java bytecode to LLVM IR
VMKit: https://vmkit.llvm.org/
The LLVM Java frontend: https://llvm.org/svn/llvm-project/java/trunk/docs/java-frontend.txt
These solutions have been developed to run Java programs natively (without going back to Java Bytecode), thus discarding valuable information like Java specific try/catch block.
They are also incomplete, because running Java natively requires a whole translation of all the standard Java libraries. Note that we don't have such problem in our project, as we intend to transform back the LLVM IR to Java bytecode.
It is also interesting to notice that the [Zing] JVM uses LLVM via [Falcon] to compile and optimize the most frequently used pieces of codes at runtime. The paper "Obfuscating Java Programs by Translating Selected Portions of Bytecode to Native Libraries" by Pizzolotto and Ceccato (2019) [2] is the one closest to what we try to achieve. Their goal is to transform the Java code to C code, while using JNI to support more complex behavior. This approach can be seen as some kind of [Cython] for Java. Note that the sources of the tool aren't available.
LLVM IR to Java bytecode
The Proteus Compile System: http://proteuscc.sourceforge.net/
The goal of these solutions is to run the LLVM bitcode within a JVM, emulating all the missing functionalities, like raw memory management. If we had reused these projects, we would have ended up with a virtual machine (the LLVM one) within a virtual machine (the JVM). We would also have had to take care of the standard Java libraries problem.
The conversion step
The Java bytecode is a high level bytecode, allowing the distribution of Java programs intended to be run on Java Virtual Machines (JVM). The bytecode cannot manipulate raw memory and is verified before being run to ensure its validity.
The LLVM IR is the Java bytecode counterpart for the LLVM compiler framework. It can be considered as a low level bytecode intended for binaries generation.
Mapping operations and data from Java bytecode to the other is not always direct as there are different trade offs that must be taken into account:
A very detailed translation from Java bytecode to LLVM IR may give more information to the obfuscator, but it may be rather difficult to go back from the LLVM version to the Java bytecode;
On the other hand, a very high level translation would yield a useless LLVM IR in terms of obfuscation, as its components are too abstract to be obfuscated by low level obfuscations.
The challenge is, thus, to find the right level of abstraction. In the following sections we describe how the mapping from Java Bytecode to LLVM IR was performed, beginning by the mapping of Java bytecode scalar and object types to LLVM IR types.
Scalar types
There are two types of numbers in the LLVM IR: integer and floating point numbers.
iN // N being the number of bits of the integer i1 // A boolean i8 // An octet i32 // A 32bit integer i1942652 // You guessed it
The type does not specify if the integer is signed or not, most of integer instructions exist in the signed and unsigned flavor.
half // 16 bits floating-point value float // 32 bits floating-point value double // 64 bits floating-point value
We will use the following type mapping:
| Java bytecode | LLVM IR |
|---|---|
| boolean | i8 |
| byte | i8 |
| short | i16 |
| char | i16 |
| integer | i32 |
| long | i64 |
| float | float |
| double | double |
The boolean type is stored using 8 bits, similarly to how Java Bytecode and the JVM works.
Objects
We consider objects as opaque pointers as we don't know (and don't want to know) what's hidden inside (that is JVM-dependent).
Note that these mappings, for objects and scalars, are inspired by those found in the [jni.h] file, the file used to write native code using the Java Native Interface (JNI).
Runtime abstraction level
We have to find the right amount of abstraction for the translated LLVM bitcode. We consider the Java bytecode to have a high abstraction level and LLVM IR to have a low abstraction level, closer to machine code.
The closer we are to machine code, the farther we are from Java bytecode and the more work we will have to do for the Java to LLVM conversion. Moreover, more code could be modified by the optimizer and obfuscator, and we could end-up with an LLVM IR whose semantic would be very hard or impossible to convert back to Java bytecode without some emulation magic. As we previously stated, we want to obfuscate the Java bytecode and try as much as possible not to end up with an LLVM interpreter within the JVM.
Having a high abstraction level, while greatly simplifying the conversion, is useless if the optimizer and obfuscator can't understand what the code is doing. We might as well put the whole Java bytecode in metadata.
For example, LLVM and Java arrays are very different. A Java array behaves much like an object, using reference, and its destruction being handled by the garbage collector. It does not make sense to use LLVM arrays so we added an abstraction. Arrays are now created and manipulated with methods taking the array pointer as an argument, much more like the way they work with Java bytecode.
Calls
We are using a variety of abstract methods to convert Java bytecode instructions that can't be directly translated to LLVM IR, like calls to other Java methods. These calls are converted using a specific convention: all the necessary information is encoded in the called function name, and the call parameters are the same as their bytecode counterparts. This makes it easy to convert back to bytecode while still allowing the optimizer and obfuscator to do their job.
For example a bytecode INVOKESPECIAL instruction will be translated to call void @"Java_@invokespecial@java/lang/Object@<init>@()V"(i64* %1).
Here calling the constructor of the target object java.lang.Object without any argument (i64* %1 is the pointer referencing this object)
We provide here a simple Java example, its corresponding Java bytecode and the generated LLVM IR:
AtomicInteger ai = new AtomicInteger(4);
Math.pow(ai.get(), 2);
NEW Ljava/util/concurrent/atomic/AtomicInteger; DUP BIPUSH 4 INVOKESPECIAL java/util/concurrent/atomic/AtomicInteger.<init>:(I)V INVOKEVIRTUAL java/util/concurrent/atomic/AtomicInteger.incrementAndGet:()I I2D LDC 2D INVOKESTATIC java/lang/Math.pow:(DD)D D2I IRETURN
%1 = call i64* @"Java_@new@java/util/concurrent/atomic/AtomicInteger"()
call void @"Java_@invokespecial@java/util/concurrent/atomic/AtomicInteger@<init>@(I)V"(i64* %1, i32 4)
%2 = call i32 @"Java_@invokevirtual@java/util/concurrent/atomic/AtomicInteger@get@()I"(i64* %1)
%3 = call double @"Java_@invokestatic@java/lang/Math@pow@(DD)D"(i32 %2, i32 2)
The same technique is also used for representing things like this which is ALOAD 0 in a non static Java methods to be used for super class instantiation.
%1 = call i64* @Java_fixed_this()
call void @"Java_@invokespecial@com/quarkslab/java2llvm/testfiles/TestFile@<init>@()V"(i64* %1)
Calls are also extensively used for Java array manipulation:
%1 = call i64* @Java_fixed_array_create_10(i32 1)
call void @Java_fixed_array_setIntCellData(%1, i32 0, i32 5)
call i32 @Java_fixed_array_getIntCellData(%1, i32 0)
With this abstraction, converting back to Java bytecode is natural, as most information required for the translation is available in the function's name.
For example the array type is specified in the array create function (the opcode 10 is for integer) without having to find the first value assignment to get the array type from.
The drawback of this approach is that we suppose that all the users of these abstract functions will be calls, and they won't end up (for instance) in an array of function pointers. This is something for instance an obfuscator could generate. This means that we need to make it aware of the special semantics of these functions.
Representation of the JVM stack
Inspired from this paper about translating bytecode to native libraries [2] , we came up with a very simple way to convert the Java stack to LLVM registers. We began by writing functions to add elements and pop elements from the stack. The stack is a simple array defined with a given length (given in the bytecode) and with an index to track where we are. We then call out special functions each time we need to interact with the stack. These functions are inlined in the final LLVM IR, and the optimizations (Scalar Replacement Of Aggregates [https://llvm.org/docs/Passes.html#sroa-scalar-replacement-of-aggregates] being the most important) completely remove the stack array.
The same technique is used for store and load operations, without the need for the index to keep track of where we are on the stack.
Note: The functions are generated at build time from C, simply because it is easier to write and to understand than the LLVM IR.
Java to LLVM
Converting from Java bytecode to LLVM IR is the easy part. Most of the bytecode instructions can be directly translated into their LLVM IR counterparts, and the stack machine is easy to emulate thanks to a simple array and index, as seen previously.
We are converting each class file as an individual LLVM module.
Because the JVM is a stack machine, there is a lot of stack-based instructions. For example the IADD bytecode instruction pops two 32 bit integers from the stack, adds them together and pushes the result on the stack. This instruction is converted to:
%1 = call i32 @Java_popInt(i64* %stackPointer, i64* %stackIndex)
%2 = call i32 @Java_popInt(i64* %stackPointer, i64* %stackIndex)
%3 = add i32 %1, %2
call void @Java_pushInt(i64* %stackPointer, i64* %stackIndex, i32 %3)
The stackPointer and stackIndex variables are values allocated at the beginning of the translated LLVM function. The maximum size of the stack is given in the original Java class file. Here is an example:
%stack = alloca [2 x i64]
%stackIndex = alloca i64
store i64 0, i64* %stackIndex
%stackPointer = getelementptr inbounds [2 x i64], [2 x i64]* %stack, i32 0, i32 0
%locals = alloca [3 x i64]
%localsPointer = getelementptr inbounds [3 x i64], [3 x i64]* %locals, i32 0, i32 0
As stated above, we are emulating a stack that will be removed by later optimizations of the LLVM bitcode.
Fox example, after conversion the following method:
public int test(int a1, int a2) {
a1 = -a1;
a1 = a1 << 1;
a2 |= 5;
a1 &= 15;
a1 = ~a1 ^ 20;
return a1 + a2;
}
gives out 105 LLVM instructions, which are then optimized to the following LLVM IR:
define i32 @"test@(II)I@1"(i32, i32) local_unnamed_addr {
lb_434176574_-1874797944:
%"7" = shl i32 %0, 1
%"12" = sub i32 0, %"7"
%"27" = or i32 %1, 5
%"32" = and i32 %"12", 14
%"40" = xor i32 %"32", -21
%"56" = add nsw i32 %"40", %"27"
ret i32 %"56"
}
Here you can see that the expression with a NOT followed by a XOR with 20 has been replaced by a XOR with -21, which is ~20 (on 32 bits, signed representation).
Control flow
The control flow is also easily converted and optimized:
public int test(int a1, int a2) {
return a1 > a2 ? a2 : a1;
}
Gives:
define i32 @"test@(II)I@1"(i32, i32) local_unnamed_addr {
lb_529116035_608112264:
%"3" = tail call i64* @Java_fixed_this()
%"9" = icmp sgt i32 %0, %1
%. = select i1 %"9", i32 %1, i32 %0
ret i32 %.
}
We can see that the implicit if instruction and the two possible result basic blocks have been combined into one using a select instruction.
The following example contains a loop:
public int test(int a1, int a2) {
int j = 0;
for (int i = 0; i < a1; i++) {
j += a2;
}
return j;
}
In the generated LLVM IR, it is optimized to a simple multiplication with a select for negative values:
define i32 @"test@(II)I@1"(i32, i32) local_unnamed_addr {
lb_1433867275_-465532616:
%"3" = tail call i64* @Java_fixed_this()
%"1121" = icmp sgt i32 %0, 0
%2 = mul i32 %1, %0
%spec.select = select i1 %"1121", i32 %2, i32 0
ret i32 %spec.select
}
The next one:
public int test(int a1, int a2) {
for (int i = 0; i < a2; i++) {
System.out.println();
}
return 0;
}
gives out:
define i32 @"test@(II)I@1"(i32, i32) local_unnamed_addr {
lb_start:
%"17.reg2mem" = alloca i32
%"3" = tail call i64* @Java_fixed_this()
%"1016" = icmp sgt i32 %1, 0
br i1 %"1016", label %lb_preloop, label %lb_return
lb_preloop:
store i32 0, i32* %"17.reg2mem"
br label %lb_loop
lb_loop:
%locals.sroa.4.017.reload = load i32, i32* %"17.reg2mem"
%"11" = tail call i64* @"Java_@getstatic@java/lang/System@out@Ljava/io/PrintStream;"()
tail call void @"Java_@invokevirtual@java/io/PrintStream@println@()V"(i64* %"11")
%"17" = add nuw nsw i32 %locals.sroa.4.017.reload, 1
store i32 %"17", i32* %"17.reg2mem"
%exitcond = icmp eq i32 %"17", %1
br i1 %exitcond, label %lb_return, label %lb_loop
lb_return:
ret i32 0
}
This loop stays as a loop because of the abstract Java functions. It would have been unrolled if it was possible.
Our last control flow example contains a switch:
public int test(int a1, int a2) {
switch (a1) {
case 0:
return 1;
case 1:
return 5;
case 20:
return 3;
case 15:
case 17:
return 666;
}
return 0;
}
resulting in the following IR:
define i32 @"test@(II)I@1"(i32, i32) local_unnamed_addr {
lb_791885625_-801122440:
%merge.reg2mem = alloca i32
%"3" = tail call i64* @Java_fixed_this()
switch i32 %0, label %lb_2054881392_-801122440 [
i32 0, label %lb_791885625_-801122440.lb_1887400018_-801122440_crit_edge
i32 1, label %lb_2001112025_-801122440
i32 15, label %lb_791885625_-801122440.lb_1288141870_-801122440_crit_edge
i32 17, label %lb_791885625_-801122440.lb_1288141870_-801122440_crit_edge12
i32 20, label %lb_314265080_-801122440
]
...
Fields
A field is a variable inside a class. It can be accessed by any method in the class and sometimes from outside the class.
We translate them as LLVM global variables. When translated back to Java bytecode, these globals will be converted back to fields.
This code:
private int test;
public int test(int a1, int a2) {
test = 9;
test += a1;
test *= a2;
return test;
}
public int getTest() {
return test;
}
Gives out:
@"Java_@test@2@I" = external local_unnamed_addr global i32
define i32 @"test@(II)I@1"(i32, i32) local_unnamed_addr {
lb_48612937_-532753336:
%"16" = add i32 %0, 9
%"25" = mul i32 %"16", %1
store i32 %"25", i32* @"Java_@test@2@I", align 4 ; A store to the variable representing the test field
ret i32 %"25"
}
define i32 @"getTest@()I@1"() local_unnamed_addr {
lb_1618212626_-532735736:
%"6" = load i32, i32* @"Java_@test@2@I", align 4 ; A load from the variable representing the test field
ret i32 %"6"
}
Exceptions
Exceptions, on the contrary, are difficult to translate to LLVM IR. There is an exception system in LLVM with throw, try/catch, cleanup pads, but it doesn't behave like the Java exception system and a lot of information that would need to be forwarded back to Java would have been lost. We need to keep in mind that LLVM is not intended to be converted to Java Bytecode.
We needed to implement our own exception system. This was done with functions representing try/catch blocks to be sure that the optimizations or obfuscations wouldn't mess them up. The exception type is encoded in metadata.
For example the following code:
public void test() {
try {
...;
} catch (RuntimeException e) {
e.printStackTrace();
}
}
is translated to the following IR, where we can see two added functions, one for the try block and one for the catch block:
define i32 @"test@()V@1"() {
...
%"6" = call i1 @Java_fixed_exception_try_1433867275(i64* %localsPointer)
br i1 %"6", label %lb_itsFine, label %lb_haltAndCatchFire
lb_haltAndCatchFire:
call void @Java_fixed_exception_catch_1433867275(i64* %localsPointer)
br label %lb_itsFine
lb_itsFine:
ret void
}
define i1 @Java_fixed_exception_try_1433867275(i64*) { ; The function for the try part of the try/catch
%9 = tail call i1 @Java_fixed_exception_result_1433867275()
ret i1 %9
}
define void @Java_fixed_exception_catch_1433867275(i64*) { : The function for the catch part of the try/catch
%"13" = tail call i64* @Java_fixed_exception_push()
tail call void @"Java_@invokevirtual@java/lang/RuntimeException@printStackTrace@()V"(i64* %"13")
ret void
}
So as long as each of the behavior of theses functions is the same, at a function level, before and after the transformations, everything is fine. In particular, we prevent the inlining of these functions, so that we can easily convert this scheme back to Java bytecode.
This is the simplest example. This system works fine for simple exceptions, exceptions with multiple catch clauses, exceptions in try or catch blocks. Problems arise when there is a jump out of the try/catch function, possibly in the middle of another one. This had to be accommodated for with switches and it made the exception conversion system quite complex.
On the other hand, translating exceptions back to Java bytecode is simple because with well defined names, finding the matching catch function for a try function is trivial.
LLVM to Java
Converting LLVM IR back to Java bytecode is more complex. Ideally, we should be able to convert back any code, but as previously stated, Java bytecode is stricter and many LLVM instructions are impossible to perform in Java without embedding an LLVM IR interpreter (as done by some LLVM to Java projects).
That being said, the LLVM IR code we generate from the Java bytecode may be further transformed by subsequent optimization or obfuscation steps. So, as we need to stick to a subset of what the LLVM IR can achieve, we may have to abort the compilation process if we end up on something we can't map back to Java.
Conversion of LLVM instructions
Here, we are going to speak about problems that can arise with specific LLVM instructions.
The first easy one is the phi instruction, classically used in an SSA form. We can easily use the already existing -reg2mem optimization to transform these into memory loads to and stores from an alloca'd variable.
The second instruction is the [GEP] instruction. Its job is to compute pointer offsets to access array or structure elements. To deal with GEP and pointers in general, we needed a points-to analysis to convert GEP instructions, figuring out if we need to access an array, an object, a local value or anything else. We need to be able to resolve all the pointed values when we are converting to Java bytecode otherwise we would need emulation at runtime. It generally works if the program is not too heavily obfuscated.
For others instructions like select instructions or operations on unsigned integers we can translate them with multiple Java bytecode instructions, but we easily end up with five times more instructions to do the same thing. When these instructions are not present we most of the time end up with smaller bytecode.
Another problem to solve is that we need to go from an SSA form back to a stack-based machine.
Back to a stack machine
The JVM is a stack machine, whereas LLVM is working with an infinite amount of registers. Thankfully, locals exist in Java bytecode.
Locals are the way of storing information inside a function when there are some operations the stack can't do, because a needed element is not at the right spot or available on the stack at all. Values can be loaded from locals (e.g. ILOAD 3 loads a 32 bit integer from the local at index 3) and put on the stack or stored from the stack to a local (e.g. DSTORE 4 stores a 64 bit floating point value in the local at index 4). The type of a local can't change during the execution of a method. There are about 65k locals available (index encoded on 16 bits) and 64 bits values like long or double take two consecutive spots.
Here is an example, describing the algorithm we use. For each instruction, LLVM easily gives us a list of the used values. The order of these values can be important, depending on whether the operator is commutative or not. So, we need the values on the stack to fit our needs for the next instruction.
For example, consider the following stack with the following values, D being at the top of the stack:
A B C D
We need the values C, D and E to be at the top of the stack for the next instruction. The algorithm finds that C and D are already at the top of the stack and that we only have to add E. E is added at the top of the stack and the next instruction can be executed.
The stack now looks like this, with R being the result of the previous instruction:
A B R
R is duplicated and stored for later use.
Sometimes, elements on the stack are not in the right order, for example:
A C D B
As the top of the stack is not useful to us and might be used in the future, we have to add our values, ending up with:
A C D B C D E //Before instruction A C D B R //After instruction
This algorithm can create large stacks of unused or unusable elements (because they are "covered" by others) so we perform a cleanup at the end of the conversion. We begin by removing useless store instructions with never used values. We then remove all stack values that are never accessed.
This algorithm is simple but does not always produce optimal results. The number of loads and stores could be reduced if the stack was managed better. There are descriptions of non trivial algorithms for conversion and optimization that could be worth implementing [3] [4] [5] .
Examples
Using only the LLVM optimizer
Here are some examples of Java bytecode converted to LLVM IR, optimized by the LLVM optimizer and translated back to Java bytecode:
0: iload_1 /* a1 */ 1: ineg 2: istore_1 /* a1 */ 3: iload_1 /* a1 */ 4: iconst_1 5: ishl 6: istore_1 /* a1 */ 7: iload_2 /* a2 */ 8: iconst_1 9: ishr 10: istore_2 /* a2 */ 11: iload_2 /* a2 */ 12: iconst_3 13: irem 14: istore_2 /* a2 */ 15: iload_2 /* a2 */ 16: iconst_5 17: ior 18: istore_2 /* a2 */ 19: iload_1 /* a1 */ 20: bipush 15 22: iand 23: istore_1 /* a1 */ 24: iload_1 /* a1 */ 25: iconst_m1 26: ixor 27: bipush 20 29: ixor 30: istore_1 /* a1 */ 31: iload_1 /* a1 */ 32: iconst_3 33: idiv 34: istore_1 /* a1 */ 35: iload_1 /* a1 */ 36: bipush 10 38: imul 39: istore_1 /* a1 */ 40: iload_1 /* a1 */ 41: iload_2 /* a2 */ 42: iadd 43: ireturn
And the bytecode after the llvm optimizations:
0: iload_1 1: ldc 1 3: ishl 4: dup 5: istore_3 6: ldc 0 8: iload_3 9: isub 10: dup 11: istore 5 13: iload_2 14: ldc 1 16: ishr 17: ldc 3 19: irem 20: ldc 5 22: ior 23: iload 5 25: ldc 14 27: iand 28: ldc -21 30: ixor 31: ldc 3 33: idiv 34: ldc 10 36: imul 37: iadd 38: ireturn
As we can see there are less instructions, from 40 down to 27, but some might have noticed that we are always using the LDC instruction, taking up a lot of bytes. We would have even less bytecode if we had simply transformed those to ICONST_1 or BIPUSH instructions
We can also observe the effects of optimizations in the following example featuring a large switch instruction:
public int test(final int a1, final int a2) {
switch (a1) {
case 0: {
return 1;
}
case 1: {
return 5;
}
case 2: {
return 3;
}
case 3: {
return 2;
}
case 4: {
return 24;
}
case 5: {
return 55;
}
case 6: {
return 99;
}
case 7: {
return 11;
}
case 8: {
return 31;
}
default: {
return 0;
}
}
}
It is converted to an array:
public int[] LLVM_swItch_table_test__II_I_1 = new int[] { 1, 5, 3, 2, 24, 55, 99, 11, 31 };
public int test(final int n, final int n2) {
if ((n & 0xFFFFFFFFL) >= 9) {
return;
}
return this.LLVM_swItch_table_test__II_I_1[n];
}
Or this loop:
int j = 0;
for (int i = 0; i < a1; ++i) {
j += a2;
}
return j;
Which is converted to a multiplication:
return a1 > 0 ? a1 * a2 : 0;
Applying some obfuscations passes with Epona
The original goal of our project is to obfuscate Java bytecode with the Epona compiler. Let's try this on some examples!
The original code is provided below. Keep in mind that the following examples are decompiled using [procyon], which might produce slightly inaccurate results:
a1 = -a1;
a1 <<= 1;
a2 >>= 1;
a2 %= 3;
a2 |= 0x5;
a1 &= 0xF;
a1 = (~a1 ^ 0x14);
a1 /= 3;
a1 *= 10;
return a1 + a2;
The following examples showcase obfuscations passes applied independently of each other.
Mixed Boolean Arithmetic:
final int n3 = n & 0x2;
final int n4 = n3 * (n | 0x2) + (n & 0xFFFFFFFD) * (n3 ^ 0x2);
final int n6;
final int n5 = (n6 = (n2 >> 1) % 3) & 0x5;
final int n7 = (n4 - 1 | 0xE) - n4;
final int n9;
final int n8 = (n9 = ((-4 - (n7 << 1) & 0xFFFFFFD6) + (n7 + 22)) / 3) & 0xA;
final int n10 = n8 * (n9 | 0xA) + (n9 & 0xFFFFFFF5) * (n8 ^ 0xA);
final int n11;
return (n10 | (n11 = -5 - n6 + n5)) - (n11 << 1) + (n10 & n11);
Opaque constants:
final int n3;
final int n4;
return ((n2 >> ((((n3 = ~n) & 0x8020080) | 0x1020D008) + ((n & 0x8020080) | 0x1090224) ^ 0x192BD2AD)) % (((n3 & 0x400000) | 0x6C124108) + ((n & 0x400000) | 0x92011075) ^ 0xFE53517E) | (((n3 & 0x20100006) | 0x6041050) + ((n & 0x20100006) | 0x8210908) ^ 0x2E35195B)) + (((((n3 & 0x4812100D) | 0x48910) + ((n & 0x4812100D) | 0x1406080) ^ 0x4956F993) & (((n4 & 0x8004D601) | 0x11002040) + ((n2 & 0x8004D601) | 0x4800008A) ^ 0xD904F6CB) - (n << ((((n4 = ~n2) & 0x11C00100) | 0x2400200A) + ((n2 & 0x11C00100) | 0x2209800) ^ 0x37E0B90B))) ^ (((n3 & 0xCD40000B) | 0x12010200) + ((n & 0xCD40000B) | 0x41C80) ^ 0x20BAE160)) / (((n4 & 0x28808280) | 0x5061100) + ((n2 & 0x28808280) | 0x1001401A) ^ 0x3D87D399) * (((n4 & 0x2000000) | 0x80C01146) + ((n2 & 0x2000000) | 0x38054820) ^ 0xBAC5596C);
We can also perform other obfuscation passes such a control flow graph flattening and combine them together. This is a simple flow before obfuscation:
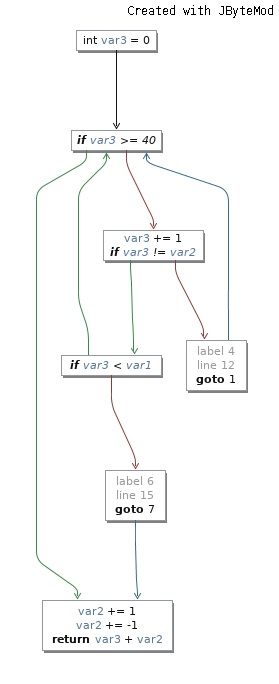
This is an extract of the same function after control flow graph flattening, visualized by the best effort of [JByteMod] tool:
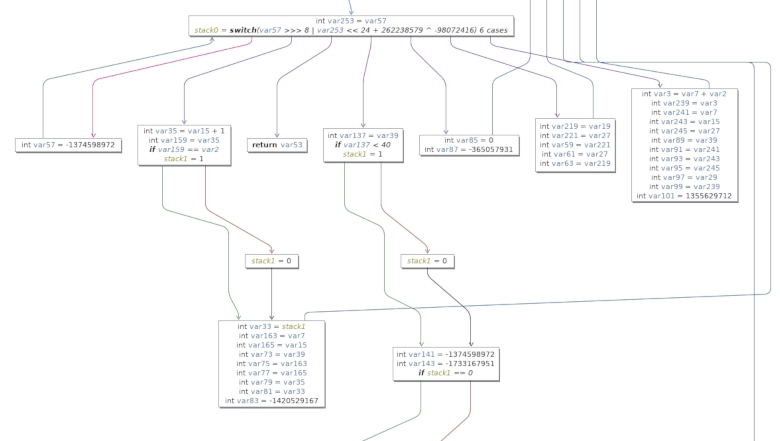
Although the generated bytecode is valid, the decompiler is struggling to make sense of it!
Current limitations
The first issue is that the LLVM to Java bytecode conversion is not 100% complete. This means that we are able to convert back only a subset of LLVM instructions. Another issue is that jumps to basic blocks located in the middle of a try/catch is not supported (which can happen in Java when using a finally block). This means that if we cannot figure out a way of translating some LLVM IR back to Java bytecode, we abort the conversion process. It usually happens when our obfuscations are too strong and we need to tweak them. This also means that we need to make our obfuscation "Java-aware", which kind of breaks a bit the original design of having "one obfuscation for all languages".
Moreover, Java annotations are not translated at all. We could embed them in LLVM metadata on each function, field or class file.
Finally, we are using an "x86_64" target triple in the LLVM IR, which is the closest we could find for representing a Java virtual machine. This is obviously a hack and creating a custom "java_bytecode" target would be better, allowing us to tweak optimization and obfuscation transformations as needed.
Conclusion
Translating Java bytecode to LLVM back-and-forth can work on toy projects and the concept still needs to be validated with real-life scenarios. The main issue is going back from LLVM without injecting a full LLVM interpreter within the generated bytecode. This involves that only a subset of the LLVM IR can be translated back to Java, and that we need to be careful as to which optimizations and obfuscations can be applied.
Going further
There are nonetheless aspects that can be improved. The first one is the Java bytecode generation: it can be implemented by a better algorithm to reduce its size. This would remove useless type conversions or ensure that we do not skip locals slots that are not used anymore thanks to previous bytecode cleanup.
Moreover we could also create custom annotations, allowing developers to specify the methods they don't want to obfuscate or want to obfuscate with heavier protection. They could be integrated as LLVM metadata that Epona could then process.
Last but not least, in order to fix the fact that we try to use the LLVM IR for something it hasn't been completely designed for, it might be interesting to experiment with [MLIR], with a custom "Java" dialect that could be used as an intermediate translation IR.
Acknowledgements
Thanks to Adrien Guinet for supervising me and helping me to write this blog post. Thanks to Béatrice Creusillet, Juan Manuel Martinez Caamaño, Matthieu Daumas and the Epona team for welcoming me, the help they provided for the project and the blog post reviews. Thanks to Quarkslab for this interesting internship opportunity.
| [Epona] | (1, 2) https://epona.quarkslab.com |
| [LLVM] | https://llvm.org |
| [Zing] | https://www.azul.com/products/zing/ |
| [Falcon] | https://www.azul.com/press_release/falcon-jit-compiler/ |
| [jni.h] | https://github.com/openjdk/jdk/blob/master/src/java.base/share/native/include/jni.h |
| [procyon] | https://bitbucket.org/mstrobel/procyon/ |
| [Cython] | https://cython.org/ |
| [MLIR] | https://github.com/tensorflow/mlir |
| [JByteMod] | https://github.com/GraxCode/JByteMod-Beta |
| [GEP] | https://llvm.org/docs/GetElementPtr.html |
| [1] | A kind of typed and structured assembly. More information here: https://llvm.org/docs/LangRef.html#introduction |
| [2] | (1, 2) Obfuscating Java Programs by Translating Selected Portions of Bytecode to Native Libraries, Davide Pizzolotto and Mariano Ceccato, 15 January 2019, https://arxiv.org/pdf/1901.04942.pdf |
| [3] | Efficiently Computing Static Single Assignment Form and The Control Dependence Graph, Ron Cytron, Jeanne Ferrante, Barray K. Rosen, Mark N. Wegman and F. Kenneth Zadeck, ACM TOPLAS, Vol 13, No 4, October 1991, http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.100.6361&rep=rep1&type=pdf |
| [4] | A Preliminary Exploration of Optimized Stack Code Generation, Philip Koopman, Jr., 1992 Rochester Forth Conference, http://users.ece.cmu.edu/~koopman/stack_compiler/stack_co.pdf |
| [5] | Global Stack Allocation -- Register Allocation for Stack Machines, Marck Shannon and Chris Bailey, 2006, http://www.complang.tuwien.ac.at/anton/euroforth2006/papers/shannon.pdf |