Authors Alexandre Adamski, Joffrey Guilbon, Maxime Peterlin
Category Reverse-Engineering
Tags TrustZone, TEE, Samsung, Android, Kinibi, programming, IDA, Ghidra, reverse-engineering, 2019
In this second blog post of our series on Samsung's TrustZone, we present the various tools that we have developed during our research to help us reverse engineer and exploit Trusted Applications as well as Secure Drivers.
Introduction
After detailing Samsung's TrustZone implementation in the first part of this series, this blog post introduces the tools that we have developed to reverse engineer the system and find vulnerabilities more easily.
Part 1: Detailed overview of Samsung's TrustZone components
Part 2: Tools development for reverse engineering and vulnerability research
Part 3: Vulnerability exploitation to reach code execution in EL3 on a Samsung device
Reverse Engineering and Tools Development
During the course of this research, we have developed quite a few different tools:
a Ghidra loader for the MCLF format used by the trustlets;
an IDA Pro/Ghidra script that renames the tlApi functions automatically;
a Python framework for communicating with trustlets;
an emulator/fuzzer based on AFL and the Unicorn engine;
a Manticore script that performs symbolic execution;
an IDA Pro/Ghidra loader for SBOOT binaries.
We're happy to announce that we are releasing all of them today!
Reverse Engineering Trusted Applications
Trustlets are located on the file system of the device as binaries. As mentioned in the previous blog post, they are in a custom file format called the MobiCore Loadable Format (MCLF). Loading these into a Software Reverse Engineering (SRE) tool like IDA Pro or Ghidra is the very first step of a journey into Samsung's TrustZone ecosystem.
Luckily for us, there already existed an IDA Pro loader called mclf-ida-loader developed by Gassan Idriss. Nevertheless, we took the time to port it to Ghidra to allow our training attendees to use free software if they wanted to.
Both loaders operate in a similar way:
they start by parsing the MCLF header of the binary;
they map the TEXT, DATA and BSS segments into memory;
they mark the entry point defined in the header;
they add a symbol for the MobiCore LIBrary handler.
The Ghidra port of the loader can be downloaded on GitHub at mclf-ghidra-loader.
As can be expected, the trustlets binaries are stripped of their symbols. But there are at least some functions that can be easily identified: the tlApi/drApi stubs. We automated this process by writing an IDAPython script, and later port it to Ghidra. This script does the following:
it loads the mapping between names and numeric identifiers;
it tries to define functions that might have been missed;
it iterates over the cross-references to the mcLib entry point;
it extracts the identifier from the stub instructions;
it renames and sets the prototype of the function accordingly.
Here is what the database looks like before applying the script:

Here is what it looks like after, with all the functions renamed:

Emulating Trusted Applications
After reversing a few trustlets, manually finding vulnerabilities and trying to exploit them, it became clear that doing it statically was not the best way to go. Some kind of dynamic analysis was needed, so we developed an emulator.
This trustlet emulator is based on the Unicorn engine (which uses QEMU) because we were already familiar with it and it provides Python bindings. It performs the same operations as the loader, but it also needs to handle the tlApi calls.
This handling is done by intercepting the control flow when it enters the mcLib. By reading the identifier that is put into the register R0, it deduces which of the tlApi was called. As a bare minimum, it needs to handle at least tlApiExit, which signals that the trustlet has finished executing, and can simply return 0 (success) for the others.
Here is a small demonstration of the emulator used on a trustlet:
The emulator is loaded with features that help during the exploitation phase. For example, it is possible to trace the instructions executed, print the values of the registers, dump the content of the stack, etc.
Fuzzing Trusted Applications
The emulator proved itself very valuable because it can be plugged into a fuzzing engine. This way, it now finds vulnerabilities automatically. No more manual analysis, which is a tedious and time-consuming process. Time is better spent exploiting these vulnerabilities or reverse engineering the other components (secure OS, monitor, etc.).
Not wanting to reinvent the wheel, we used AFL_Unicorn, an internal project developed at Quarkslab that bridges the AFL fuzzer with the Unicorn engine. But don't worry, we also ported it to AFL-Unicorn, the public project by Battelle.
A lot of the code is shared between the emulator and the fuzzing, the main differences being that:
it starts the fork server when loading is complete;
it loads the input from disk and into the TCI buffer;
it forces a crash when an Unicorn exception is raised.
Here is a small demonstration of the fuzzer finding a vulnerability:
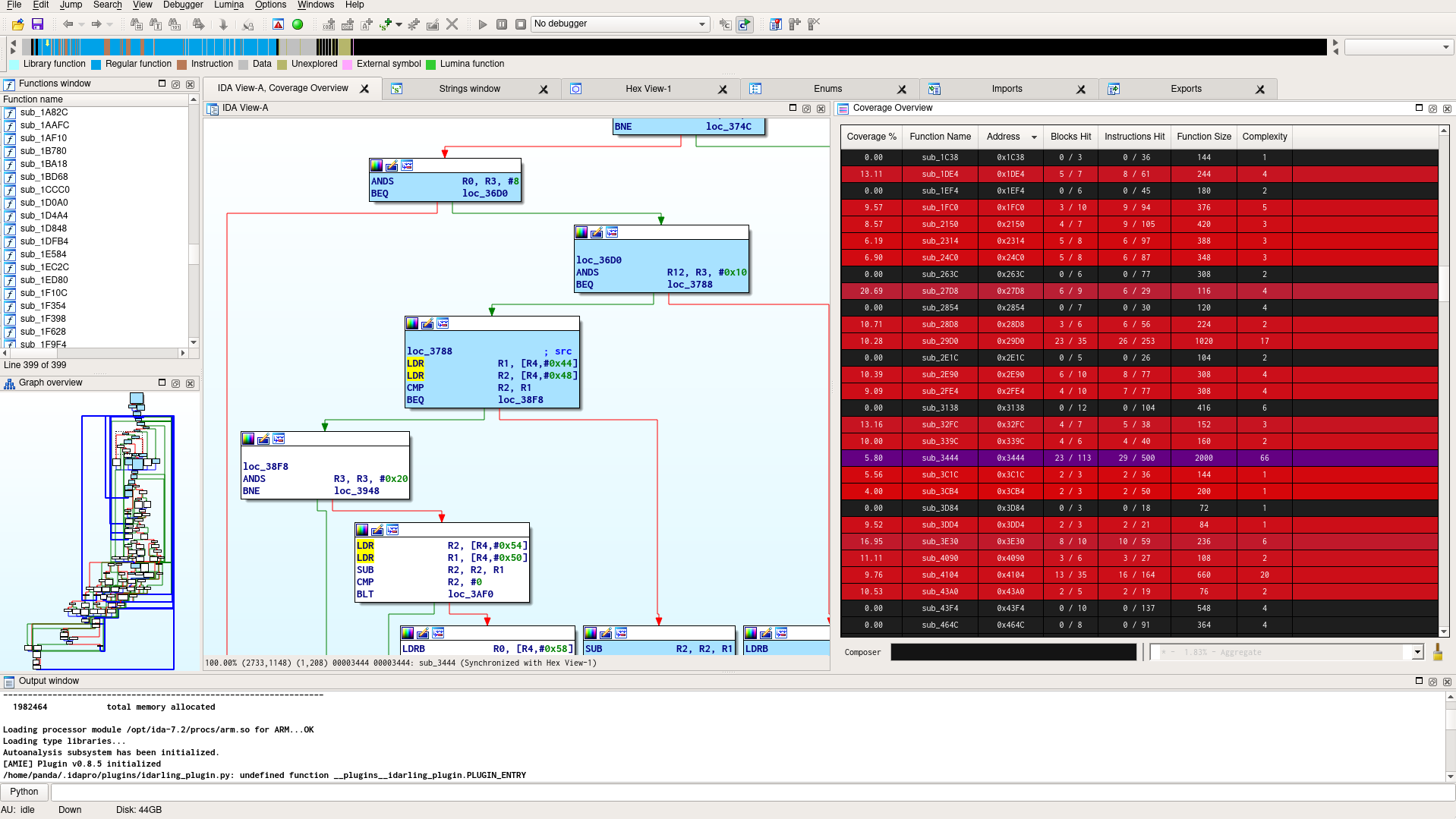
The fuzzer is able to output coverage information in the drcov format, so that it is possible to check which parts of the code might have been reached. The IDA Pro plugin Lighthouse was the perfect companion for that task.
Here is a visualization of the coverage information of a simple run:
Experimenting with Symbolic Execution
The fuzzer works fine, but we also wanted to try other techniques. So we developed a little experiment using Manticore by Trail of Bits, as the symbolic executor Triton developed by Quarkslab had no ARM support at the time.
Manticore has built-in support for loading ELF executables, so we had to convert the trustlet binaries first. Disregarding the specifics of the trustlets, we had to make a series of small patches (that have been upstreamed) to make it work.
This script roughly does the following things:
during the setup phase, it maps the TCI buffer and adds a hook on the mcLib entry-point;
when the hook is triggered, it checks which tlApi has been called:
for tlApiWaitNotification, it marks the TCI buffer as symbolic so it searches the whole input space;
for tlApiNotify or tlApiExit, the current state is terminated;
on memory accesses, it asks the solver whether the address may be invalid.
Here is a small demonstration of the script finding an invalid memory access:
Communicating with Trusted Applications
The Normal World Software Stack
As explained in the previous part, the Normal World can reach the Secure World using software interruptions and buffers of World-Shared Memory. In practice, this is implemented in the Normal World as a complex software stack.
To communicate with the Secure World, a process makes use of a native library libMcClient.so (that can also be used by applications via the Java Native Interface). This library communicates with the Mobicore Daemon (running in user-land) that can be found at /system/bin/mcDriverDaemon (or sometimes /vendor/bin/mcDriverDaemon). The daemon itself communicates with the Mobicore Driver (running in kernel-land) through a virtual device exposed at /dev/mobicore-user.
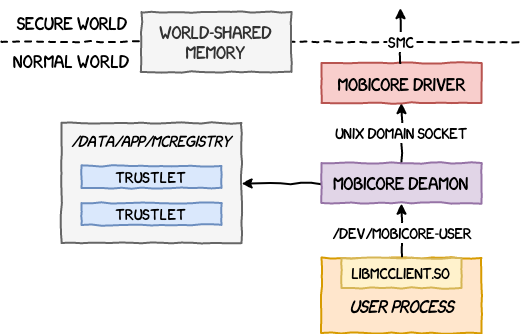
The native library exports many functions that make up the McClient API. To interact programmatically with a trustlet, an application starts by opening a session to the virtual device using mcOpenDevice (and closes it after use using mcCloseDevice). It is now able to create sessions to trustlets or drivers.
A trustlet or driver can be loaded into the Secure World by allocating the WSM buffer and using either:
mcOpenTrustlet and specifying the trustlet binary as a parameter;
mcOpenSession and specifying the trustlet UUID as a parameter.
To send a command, the application puts the command identifier and arguments into the WSM buffer, and informs the trustlet that some data is available by calling mcNotify. It then waits for the trustlet to handle the command by calling mcWaitNotification. The response identifier and return values can be found inside the WSM buffer.
Bindings and Exploitation Framework
Our tools yielded a lot of (basic) vulnerabilities, so it was time to move on to exploiting them on a real device. It is possible to use the user space components provided by Trustonic themselves on their GitHub repo, but that requires writing a lot of C code. Even using carefully crafted Makefiles, it gets old pretty fast so we made Python bindings.
These bindings, called pymcclient, interface our exploits script with the libMcClient.so library. They make extensive use of the with-statement context for cleanly handling opening and closing of sessions, and allocation and freeing of buffers. We also enriched the IPython REPL to allow us to quickly develop exploits.
Here is what such a session might look like:
In [1]: # connecting to the virtual device
...: device = McDevice(DEVICE_ID)
device.open()
In [2]: # allocating the TCI buffer
...: tci = device.malloc_wsm(TCI_BUFFER_SIZE)
In [3]: # loading the trustlet binary
...: with open(TRUSTLET_FILE, "rb") as file:
...: bs = file.read()
In [4]: # opening a session to the trustlet
...: session = McTrustlet(device, tci, bs)
...: session.open()
In [5]: # writing a command
...: tci.seek(0)
...: tci.write_dword(0x1234)
In [6]: # sending the command
...: session.notify()
In [7]: # waiting for a reply
...: session.wait_notification()
In [8]: # closing everything
...: session.close()
...: device.free_wsm(tci)
...: device.close()
Here is what it looks like using contexts:
# connecting to the virtual device
with McDevice(DEVICE_ID) as device:
# allocating the TCI buffer
with device.buffer(TCI_BUFFER_SIZE) as tci:
# opening a session to the trustlet
uuid = bytes.fromhex(TRUSTLET_UUID)
with McSession(device, tci, uuid) as session:
# writing a command
tci.seek(0)
tci.write_dword(0x1234)
# sending the command
session.notify()
# waiting for a reply
session.wait_notification()
# reading the reply
tci.seek(0)
print(hex(tci.read_dword()))
Reverse Engineering the Trusted OS
Last but not least, reverse engineering the Trusted OS requires extracting its components from the SBOOT binary, and mapping them at the appropriate addresses. We have automated this process by developing a loader for IDA Pro, and later one for Ghidra.
Conclusion
This research required a lot of tooling as, at the time we conducted it, almost no resources were publicly available. We also decided to develop new tools when we felt unsatisfied with whatever solution existed. That proved itself very valuable for our training sessions, during which we tried our best to guide our attendees through the same steps we followed. We hope that they might be useful to other people.
The next blog post in this series will detail the vulnerabilities we found and the exploits we developed to reach code execution in EL3. One of these vulnerabilities has yet to be patched and we are still waiting for the approval of the vendor to publish. In the meantime, feel free to contact us if you have any questions.