Author Jonathan Salwan
Category Program Analysis
Tags DSE, DTA, challenge, Triton, program analysis, 2018
This micro blog post introduces our research regarding symbolic deobfuscation of virtualized hash functions in collaboration with the CEA and VERIMAG.
1 - Introduction
Since 2016 we have been playing around symbolic execution and binary deobfuscation in order to (1) test and improve our binary protector (Epona) (2) improve our DSE (Dynamic Symbolic Execution) framework (Triton). Last week we published at DIMVA 2018 a part of this research focusing on attacking virtualization based-software protections and specially when hash functions are virtualized in order to protect integrity checks, identifications etc. For this study we relied on an open-use source protector (Tigress) and provided scripts and results of our attack as well as some solutions of the Tigress challenge.
Everything is explained in detail in the paper but we will summarize the key points and results of our approach in this micro blog post.
2 - Our approach
Our approach relies on a key intuition which is that a virtualized trace combines instructions from the original program behavior and instructions from the virtual machine processing. If we are able to distinguish these two subsets of instructions, we are able to avoid instructions from the virtual machine processing and only keep instructions which are part of the original program behavior. In order to do that, we need to identify the inputs of the virtual machine and we both taint and symbolize these inputs. Then we perform a dynamic symbolic execution guided by the tainted informations and concretize everything that is not tainted. It means that we concretize everything which is not related to the VM's inputs and so, we only keep instructions that are part of the original program behavior - in others words, we avoid instructions that are part of the virtual machine processing using our tainted-based concretization policy. At the step we are able to devirtualized only one path, so in order to devirtualize the whole program behavior, we perform a dynamic symbolic exploration based on our first symbolic execution, and then, we build a path-tree of symbolic expressions based on the symbolic exploration. Now that we have the whole program behavior as symbolic expressions (without the virtual machine processing), we translate our symbolic representation into the LLVM-IR one and then we recompile a new binary without the virtualization protection.
3 - Experiments
To evaluate our approach we made two kinds of experiments, the first one on a controlled setup and the second one on an uncontrolled setup which is the Tigress challenge. Then we defined three criteria:
- Precision
Correctness: Is the deobfuscated code semantically equivalent to the original code?
Conciseness: Is the size of the deobfuscated code similar to the size of the original code?
Efficiency (scalability): How much of RAM/Time?
Robustness w.r.t. the protection: Do specific protections impact our analysis more than others?
3.1 - Controlled Experiment Setup
In the controlled setup we picked up 20 hash algorithms and 46 different Tigress protections (all related to virtualization, like different kinds of dispatchers, operands...) and then we compiled each one of these hash algorithms with the different protections, so which gave us a dataset of 920 protected samples. The goal was to devirtualize these samples using our approach (script here) and compare results (according to previous criteria) with original versions. Results are that we are semantically correct for all samples with a size close to the original one, and even, smaller than original one in some cases (see following tables (b)).
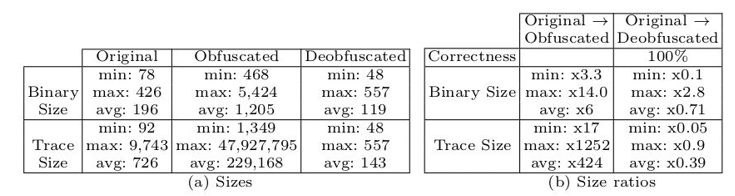
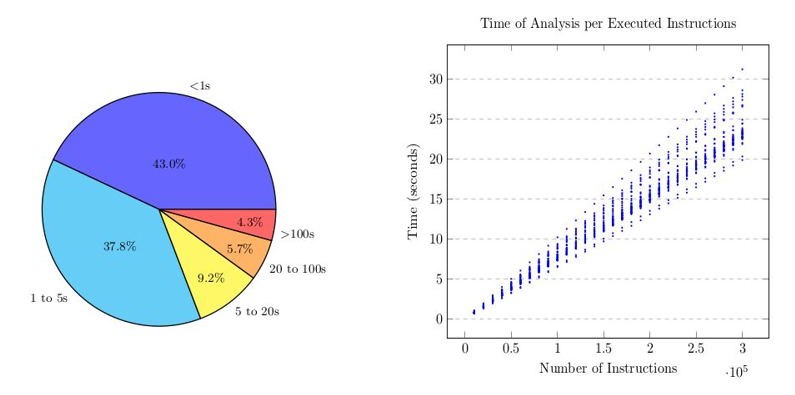
Regarding the efficiency of our approach, we have a linear time of analysis according the number of executed instructions. We successfully devirtualized a major part of our samples in less than 5 seconds (see following figures). Worst samples took more than 100 seconds which are basically samples containing two levels of virtualization and involved about 50 millions of instructions.
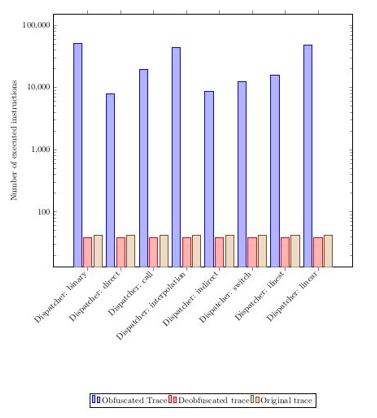
Then, regarding the robustness of our approach, we noted that the conciseness of our approach was not dependent of the applied protection. For example, if we virtualize the MD5 hash algorithm with 46 different protections (and so 46 different protected binaries) and then we apply our approach to devirtualize these 46 different versions of the protected MD5 algorithm, we get as result 46 devirtualized versions with the same conciseness for all of them. The following figure represents the number of instructions for the original (brown), protected (blue) and devirtualized (red) version of a same program for all kinds of dispatchers. We can quickly see that the number of instructions of the protected version (blue) is different according the dispatcher used, but after our analysis, whatever the dispatcher used, we recovered the same number of instructions (red) which is close to the number of instructions of the original version (brown). See more detail and metric results in the paper.
3.2 - Uncontrolled Experiment Setup (Tigress challenges)
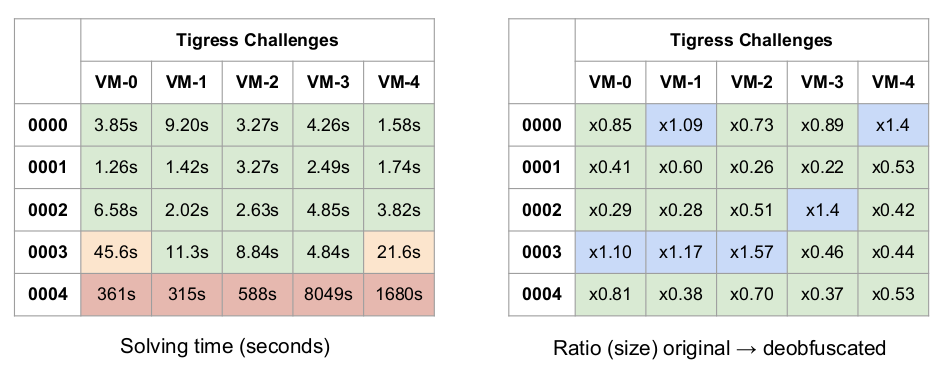
We also confronted our approach to the Tigress challenges. The challenge consists of 35 virtual machines with different levels of obfuscation (see following table). All challenges are identical: there is a virtualized hash function f(x) -> x' where x is an integer and the goal is to recover, as close as possible, the original hash algorithm (all algorithms are custom). According to their challenge status, only challenge 0000 had been previously solved and October 28th, 2016 we published a solution for challenges 0000 to 0004 with a presentation at SSTIC 2017 (each challenge contains 5 binaries, resulting in 25 virtual machine codes). We do not analyze jitted binaries (0005 and 0006) as jit is not currently supported by our implementation.
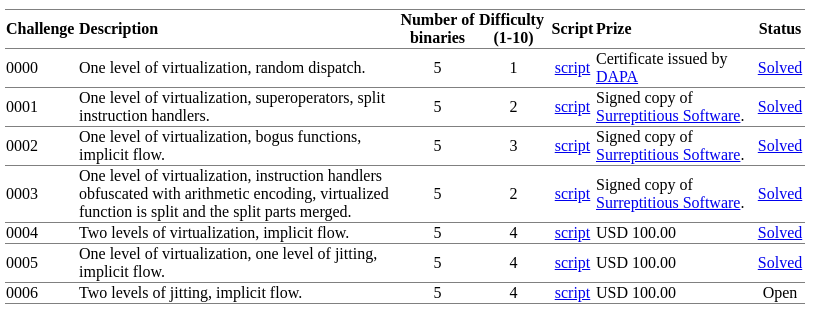
We have been able to automatically solve all the aforementioned open challenges in a correct, precise and efficient way, demonstrating that the good results observed in our controlled experiments extend to the uncontrolled case. Correction has been checked with random testing and manual inspection. The hardest challenge family is 0004 with two levels of virtualization. For instance, challenge 0004-3 contains 140 millions of instructions, reduced to 320 in 2 hours (see following tables).
4 - Limits and Mitigations
One of our main limit is that our approach is geared at programs with a small number of tainted paths, which is not a problem for hash algorithms but may be a strong limit for others virtualized programs like malware. Then our DSE model (which is Triton) does not support user-dependent memory access. Then multithreading, floating point arithmetic and system calls are out of scope of our symbolic reasoning. Also, as our approach is based on a dynamic analysis, loops and recursive calls are unrolled which may increase considerably the size of the devirtualized code.
Potential defenses could be to attack our steps like killing the taint or spreading it as much as possible to influence our preciseness. It also could be possible to kill our dynamic symbolic exploration adding some hash conditions relying on tainted data (VM's inputs), as explained in a previous blogpost. Example: if (hash(tainted_x) == 0x123456789) where hash() is a cryptographic hash algorithm. If we cannot explore the whole program behavior, it will result in an incorrect devirtualized version of the program.
Another interesting defense is to protect the bytecode of the virtual machine instead of its components. Thus, if the virtual machine is broken, the attacker gets as a result an obfuscated pseudo code. For example, this bytecode could be turned into unreadable Mixed Boolean Arithmetic (MBA) expressions.