Authors Adrien Guinet, Romain Thomas
Category Software
Tags instrumentation, loader, LIEF, software, 2021
This blog post introduces QBDL (QuarkslaB Dynamic Loader) as well as a use case which runs NVIDIA NGX SDK under Linux. You can take a look at the project on Github: https://github.com/quarkslab/QBDL .
What's QBDL?
QBDL (QuarkslaB Dynamic Loader) is a cross-platform library that enables to load ELF, PE and Mach-O binaries with an abstraction on the targeted system. It abstracts the memory model on which the binary is loaded and provides an enhanced API to the user to process symbols resolution. In a nutshell, it makes it possible to load binaries on a foreign system without reinventing the wheel.
The project is written in C++ and we provide Python bindings for ease of convenience.
Why QBDL?
It turns out that various loaders for ELF, PE and Mach-O binaries already exist but most of them are OS-dependent and basically, we have one project for each format. These existing libraries target a specific system so we can't, for example, leverage the Wine PE loader to load a Windows executable in Unicorn. Here is a non-exhaustive list of such projects:
https://github.com/malisal/loaders: small, self-contained implementations of various binary formats loaders. Unfortunatly, it is not possible to load on a foreign system.
https://github.com/shinh/maloader: a userland Mach-O loader for Linux
https://github.com/taviso/loadlibrary: a library that allows native Linux programs to load and call functions from a Windows DLL
https://github.com/polycone/pe-loader: a userland PE loader for Windows
The purpose of QBDL is to have a single library to load these formats with enough modularity to cover various use cases:
Loading in a native process (e.g. running a PE on Linux).
Loading in a lightweight sandbox such as Unicorn, Miasm or Triton
In the other hand, QBDL does not aim to provide a full operating system implementation like Wine or Darling and does not have the best performance out of all dynamic linkers.
QBDL has been designed with the same mindset as the other tools developed at Quarkslab (QBDI, Triton, LIEF, ...): provide a modular library with a user-friendly API that can be used in different projects or various contexts.
How does it work?
QBDL uses LIEF to parse the executable formats and interprets the information it provides to load the given ELF, PE, or, Mach-O binary according to the system abstraction indicated by the user.
As explained in the previous section, one of the features of QBDL is to provide an abstraction over the memory model. In other words, it enables users to define their own implementation of mmap, mprotect, ... according to the underlying system.
This abstraction is performed by overriding functions used in the different stages of the loading process:
class TargetMemory {
virtual uint64_t mmap(uint64_t hint, size_t len) = 0;
virtual bool mprotect(uint64_t addr, size_t len, int prot) = 0;
virtual void write(uint64_t addr, const void *buf, size_t len) = 0;
virtual void read(void *dst, uint64_t addr, size_t len) = 0;
};
If we aim at loading the binary on a POSIX compliant system, we can simply override the read() function with a memcpy() implementation:
inline void read(void *dst, uint64_t addr, size_t len) override {
return memcpy(dst , (void *)addr , len);
}
On the other hand, if we target Triton, the dynamic symbolic execution engine developed at Quarkslab, we will use the getConcreteMemoryAreaValue() function:
class TritonVM(pyqbdl.TargetMemory):
def __init__(self, ctx: TritonContext):
super().__init__()
self.ctx = ctx
def read(self, ptr, size):
return self.ctx.getConcreteMemoryAreaValue(ptr, size)
LIEF uses these abstracted functions in the different steps of the loading process:
| Steps | Functions |
|---|---|
|
mmap(), write(), mprotect() |
|
read(), write() |
|
symlink(), write() |
In the last step, symbols resolution, we use another user-provided function: symlink(), that takes a symbol as input and returns the address of the symbol that should be bound by the loader.
As this function is managed by the user, it enables to completely control how symbols are resolved.
Symbols resolution
The three executable formats ELF, PE and, Mach-O supported by QBDL use different mechanisms to bind imported symbols. This section introduces these differences and how they are managed in QBDL's loaders.
ELF: plt/got
In the ELF format, when the binary is compiled to use the plt/got mechanisms, the imported symbols are associated with a specific relocation type: R_X86_64_JUMP_SLOT. This relocation provides information about the offset of the Global Offset Table (GOT) that is used for the plt/got trampoline mechanism.
$ readelf -r ./elf.bin
Relocation section '.rela.plt' at offset 0x348 contains 3 entries:
Offset Info Type Sym. Value Sym. Name + Addend
0000006008f8 000100000007 R_X86_64_JUMP_SLO 0000000000000000 printf@GLIBC_2.2.5 + 0
In this case, the offset of the relocation (0x6008f8) points to an entry in the .got.plt that can hold two values depending on the loading parameters:
Lazy bind: *(0x6008f8) contains the address of the push/jmp instructions that are used to resolve the function.
Bind now: *(0x6008f8) contains the resolved address of the function.
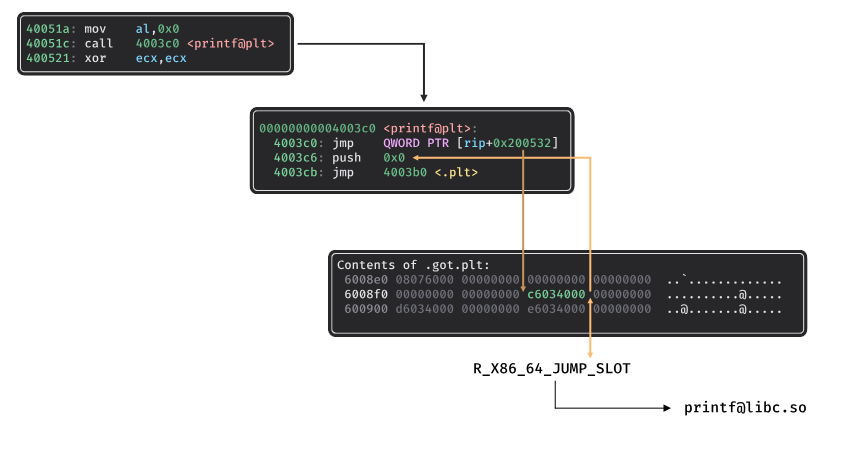
When loading an ELF binary with QBDL, we ask the user to provide the addresses of the imported functions through the symlink() function. These values are used by the QBDL's loader to fill the address associated with the relocation described previously.
In the case where the binary is compiled without the plt/got mechanism, we have to deal with another kind of relocation (R_X86_64_GLOB_DAT) but the process remains the same:
const uintptr_t addr_target = base_address_ + reloc.address();
// [...]
case RELOC_x86_64::R_X86_64_GLOB_DAT: {
const uintptr_t addr = engine_->symlink(*this, reloc.symbol());
engine_->mem().write_ptr(binarch, addr_target, addr + reloc.addend());
break;
}
Mach-O: Binding bytecode
The process to resolve imported symbols in the Mach-O format is very close to the ELF one. Nonetheless, instead of having a relocation table that provides information about the symbols, we have to interpret a bytecode. This bytecode is composed of few opcodes, associated with ULEB-128 integers and other primitives. It can be seen as a DSL (Domain Specific Language) that embeds, and compresses, the information about the relocations and the symbols resolutions.
The following figure shows the differences between the Mach-O bindings bytecode and the ELF relocations table.

In QBDL, we process these bindings with the following piece of code:
for (const BindingInfo &info : binary.dyld_info().bindings()) {
// [...]
const auto &sym = info.symbol();
const uint64_t ptrRVA = get_rva(binary, info.address());
const uint64_t ptrAddr = base_address_ + ptrRVA;
const uint64_t symAddr = engine_->symlink(*this, sym);
engine_->mem().write_ptr(binarch, ptrAddr, symAddr);
}
PE: IAT
Finally, PE binaries handle imported functions differently from ELF and Mach-O. In PE binaries, the imported functions are associated with two tables:
Lookup Table.
Import Address Table (IAT).
Before loading the PE binary, these two tables contain the same values: the function names offsets (or the ordinal value if loaded by ordinal). When the binary is loaded, the Lookup Table keeps the function names offsets while the values of the Import Address Table are replaced with the absolute address of the resolved function.
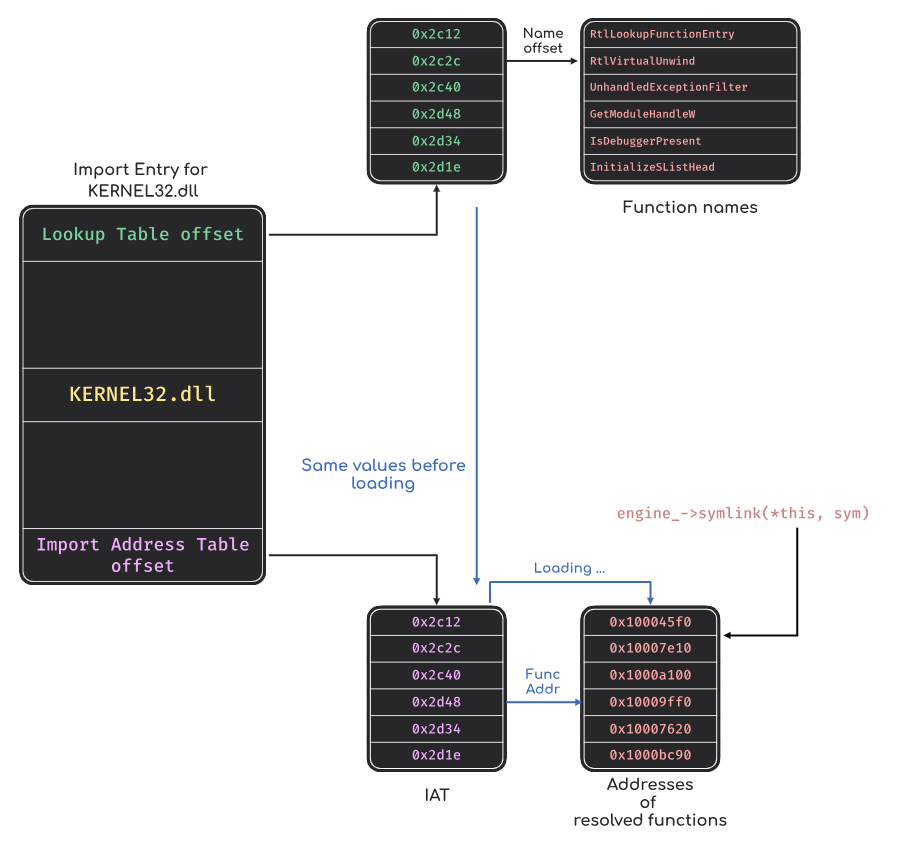
Therefore, the PE loader of QBDL updates the Import Address Table with the value returned by the symlink function:
for (const Import &imp : binary.imports()) {
for (const ImportEntry &entry : imp.entries()) {
const uint64_t iatAddr = entry.iat_address();
LIEF::Symbol sym{entry.name()};
const uintptr_t symAddr = engine_->symlink(*this, sym);
engine_->mem().write_ptr(binarch, base_address_ + iatAddr, symAddr);
}
}
Let's know dig into a concrete use case of QBDL.
Use case: running the NVIDIA NGX SDK under Linux
In this section, we'll see how to leverage QBDL to run the Windows-only NVIDIA NGX SDK. We are going to introduce what NGX is, take a high-level view of its architecture, figure out the various challenges of this task and finally make it happen!
What is NVIDIA NGX?
NVIDIA NGX is an SDK provided by NVIDIA that uses machine learning techniques to provide image and video enhancement algorithms, like upscaling, slow motion or image reconstruction. It is also the framework used by DLSS, an upscaling technology tailored for video games.
In order to download the SDK, you need to register to the NVIDIA Developer program [1]. At the time of this writing, it is free, and access is granted directly. Unfortunately, only a Windows version is provided.
That being said, NVIDIA announced in 2020 [2] that the NGX library was shipped to Linux starting from the 450.51 driver. Let's understand what is really shipped and what is missing, by first understanding how all of this works.
NGX architecture
First of all, NGX is only made of userland components, no specific driver interface is involved. It relies on the Direct3D, Vulkan and/or CUDA APIs (depending on the component).
The first main component is the NGX shared library, which is:
nvngx.dll on Windows.
libnvidia-ngx.so on Linux (can be found on Debian systems in /usr/lib/x86_64-linux-gnu/libnvidia-ngx.so).
These components expose the final user API, that is for instance used in the sample provided in the NGX SDK archive. Then, each NGX "feature" is implemented in a dedicated shared library:
Image Super Resolution (isr): nvngx_dlisr.dll.
In-Painting (inpainting): nvngx_dlinpainting.dll.
Video Super Resolution (vsr): nvngx_dlvsr.dll.
Slow Motion (slowmo): nvngx_dlslomo.dll.
The Linux NGX implementation (libnvidia-ngx.so) looks for libnvidia-ngx-dl{feature}.so files (e.g. libnvidia-ngx-dlisr.so). These ELF shared libraries are not publicly provided by NVIDIA.
The last component of the NGX framework is the updater. It is implemented within the ngx-updater binary under Linux, and is transparently launched by the libnvidia-ngx.so component. According to the documentation [3], its role is to download updated machine learning models for each feature. We didn't try to reverse engineer that part.
So the missing bits with the current NGX Linux version are the implementation of the actual features (the libnvidia-ngx-dl*.so files). In the next sections, we will use QBDL to implement them based on their Windows counterparts.
Challenges
We started with the NGX feature that looked like the easiest one: Image Super Resolution (nvngx_dlisr.dll). Indeed, in terms of data, it looks like it takes an image, upscales it, and regenerates an image. No video processing in the middle.
After a quick look at nvngx_dlisr.dll libraries, we can see that:
It imports functions from the cuDNN [8] library. Good news for us, it also exists natively for Linux.
It imports functions from the Windows API (kernel32.dll, user32.dll & so on). We will have to implement some of them, or at least emulate the behavior we need.
The Visual C runtime library (aka MSVCRT) is statically linked.
The NVIDIA CUDA runtime is also statically linked.
So we have a few challenges ahead, and others we discovered while making this happen:
Signature verification on shared libraries.
Setting up a valid Windows environment for MSVCRT to work (or, more exactly, how not to do it).
Making the CUDA runtime work.
Let's describe these in the following sections.
Bypassing signature verification
The libnvidia-ngx.so main library verifies a signature within the nvngx_dl*.so files, which should be in a .nvsig section. We didn't take the time to reverse engineer the format of this signature. Indeed, even if we knew how to sign, chances are we wouldn't have a valid private key to sign our wrapping binary. So, whatever happens, we either need to patch libnvidia-glx.so to change a potential public key/root of trust that is used to verify the signature, or to just bypass that signature. We chose the second option.
This is basically only modifying a flag passed to the function at address 0x6EF00, which is responsible for loading these .so plugins. This is done by patching the code in memory.
The static library problem
The NGX runtime libraries are linked with the static Visual C RT library. This means that all the necessary C and C++ library implementations are shipped within the shared libraries. While this is theoretically fine, these implementations rely on many components of the Windows OS (e.g. the PEB). Even if it is possible to setup a PEB-like structure under Linux [4] - as Wine does -, it is not something QBDL provides at this point.
The same kind of issue arises with the CUDA runtime: it is also statically linked. The CUDA runtime makes calls to the CUDA userspace driver, but some structures are not defined and would require further reverse engineering. wine-staging contains such a wrapper [6], but using them involved many CUDA-related failures in our case. It would be better to directly call the Linux CUDA runtime libraries.
One idea to fix these problems is to identify the entry points of these static libraries within the NGX's DLL, and hook them. This is far from ideal, as it binds our QBDL wrapper to a specific version of the NGX libraries (e.g. with this version-specific list of offsets), but it made the whole thing work in the end.
IDA provides a signature mechanism named FLIRT [5]. It first creates a signature database from a static library with symbols, and then searches for these signatures in our DLLs. How to do this is out of the scope of this blog post, but this article is a good reference.
Putting everything together
The final wrapper can be downloaded here: https://github.com/quarkslab/nvidia-ngx-wrapper. Please follow the README for build & usage instructions.
In the end, we generate a libnvidia-ngx-dlisr.so shared library that uses QBDL to load nvngx_dlisr.dll, and then uses the Linux implementation of cuDNN & the CUDA runtime. This is all called through the NGX Linux interface implementation (in libnvidia-ngx.so). One last detail we didn't mention yet is that we need to adapt the interface of an NGX C++ virtual interface (that is used to basically describe options) from the MSVC C++ ABI to the Linux one [7]. This is necessary because the order of the functions in the vtable is not the same between the two ABIs. Having tools that automate that kind of wrapping would greatly help (an idea for yet another Clang-based project?).
In the end, here is an example of the wrapper in action that uses NGX to upscale an image:
With the original and upscaled image:


Conclusion
QBDL can be simply described as a cross-platform binary loader library, with the particularity of abstracting the targeted system so that it can be easily adapted to many scenarios. Using it in real-life situations shows the limits of only providing a loader if we want to actually run code (like the missing PEB emulation on Windows). Future QBDL releases might focus on this problem and provide some of the common OS low-level structures and setup necessary to be able to run code.
If you are interested, you can also have look at the presentation @sstic 2021 (in French), and the slides.
Acknowledgments
As always, thanks to Béatrice Creusillet for her valuable reviews of Quarkslab's blog posts!
References
| [1] | https://developer.nvidia.com/ngx-ea-program |
| [2] | https://www.phoronix.com/scan.php?page=news_item&px=NVIDIA-450.51-Linux-Driver |
| [3] | https://download.nvidia.com/XFree86/Linux-x86_64/455.38/README/ngx.html |
| [4] | Thanks to kernel support: https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/segment.h#L73 |
| [5] | https://hex-rays.com/products/ida/tech/flirt/in_depth/ |
| [6] | https://github.com/wine-staging/wine-staging/tree/master/patches/nvcuda-CUDA_Support |
| [7] | https://github.com/quarkslab/nvidia-ngx-wrapper/blob/b915d093969b9c4e644ad87d7a754de736bfd168/lib/core/ngx_wrapper.h#L36-L111 |
| [8] | NVIDIA CUDA Deep Neural Network library: https://developer.nvidia.com/cudnn |