Authors Pierrick Brunet, Béatrice Creusillet, Adrien Guinet, Juan Manuel Martinez Caamaño
Category Programming
Tags obfuscation, software, programming, 2019
This blog post demonstrates through an example how the Epona obfuscating compiler, from the Epona Application Protection Suite, achieves the challenge of facilitating the everyday experience of its users while enabling better obfuscation schemes trade-offs.
Introduction
Code obfuscation aims at protecting the intellectual property of applications delivered in an unmanaged environment. The process usually involves selecting and successively applying various transformation techniques, for instance at compile time, with the goal of providing a good trade-off between protection and performance. However, solving this problem is known to be very difficult as the selection of the assets to protect is application and context dependent, the number of transformation combinations can be overwhelming, and modeling the transformation combinations impact on performances can be tricky.
Obfuscators thus usually rely on some guidance from the users, but this displaces the responsibility of the protection quality on their shoulders. Some feedback about the effects of the transformations is then necessary for the users to be able to assess the requested protection.
Therefore, developing a code obfuscator amounts to solving several paradoxes: hiding code and data to the attacker vs. providing traceability for the user; balancing obfuscation quality vs. performance penalty; ensuring obfuscation diversity vs. ease of usage.
In this blog post, we demonstrate through a running example how Epona achieves the challenge of facilitating the everyday experience of its users while enabling better obfuscation schemes trade-offs.
We show how the user can define a tailored scheme to protect an application, and then check some obfuscation properties of the generated application to get a preliminary idea about the quality of the obfuscation scheme without having to immediately refer to a reverser. We also also show the need for high level pre-defined obfuscation schemes that combine several passes and are able to specifically target intermediate obfuscation passes artifacts.
But first, let us see what Epona is.
Epona: a short overview
Epona is the code obfuscator part of the Epona Application Protection tool suite developed by Quarkslab. It targets C/C++/Objective-C codes and generates obfuscated binaries, always respecting the original semantics of the program. The obfuscator is delivered as a compiler, compatible with others such as GCC, Clang and the Microsoft Visual Studio compiler.
Epona is built on top of the LLVM compiler infrastructure. LLVM is a compilation toolchain that became widespread due to its modularity and ease of extension. Its main feature is the definition of a bitcode, called the LLVM Intermediate Representation or LLVM IR, which is used to communicate by the different projects that are part of the framework. Among these projects, we can highlight:
the front-end, Clang, that translates C/C++/Objective-C codes to LLVM IR;
the optimizer, which applies a series of optimizations over this representation;
and the backends that translate this representation to assembly code for a particular target architecture.
Epona takes the form of a series of code obfuscations implemented as transformations applied by the optimizer. Additionally, some extensions in the front-end allow Epona to interpret user annotations embedded in the input source code to describe an obfuscation scheme. These annotations are further discussed in the following section.
The order in which the code transformations are executed is key to achieve a performant code, all the more when mixing optimizations and obfuscations [2]. If obfuscations were performed before LLVM optimizations, the generated code would be too slow, since obfuscations tend to defeat the precise analyses required for an effective optimization. Epona thus performs a first round of optimizations over the input code, to be used as a starting point for obfuscations. Then, obfuscations are applied successively according to the command line options or the user directives, and a final round of optimizations is performed to clean up the obfuscated code (as shown in the next picture). An obfuscation is considered as being successfully applied if it is still present in the final generated code after the last round of optimizations.
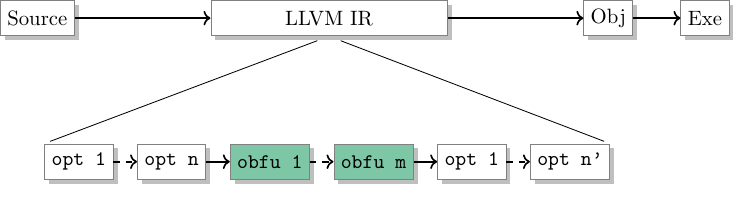
Interacting with Epona
In a traditional compiler, there is little interaction between the user and the compiler: the choice of the user is restricted to a few optimization levels, or tweaking certain flags to enable/disable different features of the compiler. Furthermore, the set of optimizations run for each optimization level is fixed to a predetermined sequence of optimizations which are applied all over the code in a successive manner.
The situation is different in our obfuscator. Epona provides the means for the user to select a proper obfuscation scheme that will satisfy her/his required security and performance constraints.
In Epona, this scheme consists of a sequence of obfuscations to apply, the parts of the code over which they are performed, and values for the different options that control the obfuscations. There are three main ways to describe obfuscation schemes:
the command-line interface;
annotations, taking the form of pragmas, which can request global obfuscations over the current compilation unit or target some specific code elements;
YAML configuration files.
From these obfuscation specifications, Epona produces an obfuscated binary. The next step is to ensure that the scheme has correctly been applied on the code. The classical solution is to ask a reverse engineer to audit the binary. This approach remains time-consuming, and may induce inconvenient delays in the workflow.
Epona provides two different methods to ease this task, and to allow a non-expert user to check whether an obfuscation scheme has been successfully applied, and if not, to find out the reasons why:
Remarks: Epona leverages the LLVM diagnostic mechanism to provide rich information about the execution or non-execution of its obfuscations; the result can then be visualized in a browser, as code annotations.
Epona Report tool: this tool relies on summaries of the original source codes and the obfuscated binary, built during the compilation, which can be contrasted to study how a code was transformed, and answer different kind of questions:
is the global variable 'X' encrypted?
are there multiple versions of the function 'Foo'?
are there anti-debug checks inserted in 'main.cpp'?
...
These questions take the form of a user-provided Python script with a list of checks to be performed over the summaries. The tool is executed by the user after the compilation and gives an immediate feedback on the obfuscation scheme.
In the next sections, we show what a user workflow on a simple example may be, and how the different reporting tools can help the user untangle the effects of obfuscations and their relative ordering.
A simple running example
We start from the code below, in which the user wants to:
encrypt and sign the global variables to ensure confidentiality and integrity.
sign and verify the code to ensure these global variables are the ones used in the code during its execution.
static const float Gx[] = {1.f, 2.f, 4.f, 5.f};
static const float Gy[] = {2.4f, 2.1f, 4.8f, 5.9f};
void foo(float* Vec, size_t N)
{
for (size_t I = 0; I < N; ++I) {
for (size_t J = 0; J < 4; ++J) {
Vec[I] *= Gx[J];
Vec[I] += Gy[J];
}
}
}
Global data protection
Epona provides the GlobalArrayEncryption pass which applies an encryption function to global arrays initial values. The arrays are decrypted at runtime. The GlobalArrayIntegrity pass computes checksums of global arrays and checks them at runtime.
Within Epona, pragmas requesting global obfuscations over the current compilation unit are interpreted from bottom to top. So, if we want to encrypt the global variables Gx and Gy, and then sign them, we need to add the following annotations at the beginning of the code:
#pragma epona global obfuscate GlobalArrayIntegrity(filter="Gx|Gy")
#pragma epona global obfuscate GlobalArrayEncryption(filter="Gx|Gy")
Now we have our scheme, let's verify with the Epona Report tool that everything ran as expected. The following Python script can be used to verify whether the global variables Gx and Gy have actually been obfuscated as expected in the generated LLVM IR:
from epona import check
check.global_encrypted("Gx|Gy")
check.global_integrity_check("Gx|Gy")
It is triggered by the following commands, where the first one generates the binary and the second one performs the checks:
epona -mllvm --report-output-dir=${work_dir}/report-dir example.c
epona-report ${work_dir}/report-dir --source=example.cpp --verify=../verify_script.py
The issued report tells us that nothing has been encrypted and that no integrity checks have been added. Here, we need to understand why it doesn't work as expected in order to fix the problem. Having a look at the Remarks [1] emitted through LLVM by the obfuscations may give us an idea about what happened. Sadly, the Remarks tell us that nothing happened when the optimization level is at least O2, which suggests that LLVM optimizations perform modifications that hinder the obfuscations.
Indeed, the next series of events happened under the hood:
the code is first optimized thanks to LLVM's optimizations;
obfuscations are applied;
a subset of LLVM's optimizations is re-applied.
During the first optimization step, LLVM scalarized the contents of the two global variables Gx and Gy, and used them directly as constants. It has the right to do so because they are declared as immutable (thanks to the const keyword). This highlights that the internal behavior of the compiler may have a huge impact on the obfuscation scheme and that there is a real need to check whether the obfuscator actually performs the desired modifications.
One solution to prevent this optimization is to use the volatile specifier for Gx and Gy. In this particular case, this is a flawed solution because it will enforce unnecessary memory accesses ordering; moreover, the volatile qualifier will remain when we will re-apply the optimizations at the end of the compilation process, thus hindering possible optimizations. Epona should deal with these issues transparently for user as Gx and Gy are identified as targets of obfuscations from the beginning.
For the moment, adding the volatile qualifier remains the simplest solution. Once this addition in the source code has been done, the script in the preceding Epona Report Python script still raises an issue: the integrity of the global arrays is not checked as specified. Asking for Remarks give us the following output:
file.c:1:1: remark: Encryption done [-Rpass=EPONA-GlobalArrayEncryption]
static volatile const float Gx[] =
^
file.c:1:1: remark: Not constant global variable. [-Rpass-missed=EPONA-GlobalArrayIntegrity]
static volatile const float Gx[] =
^
We now see that encrypting variables makes them lose their const qualifier, hence making them mutable. Per design, we cannot test the integrity of mutable global variables, as their values can change during the program execution (which is the case here because they will be decrypted at runtime).
One solution is to invert the order of the operations:
#pragma epona global obfuscate GlobalArrayEncryption(filter="Gx|Gy")
#pragma epona global obfuscate GlobalArrayIntegrity(filter="Gx|Gy")
After that, the Epona Report Python script confirms that everything happened as expected.
This illustrates the need to ease the work of the user by exposing a higher-level obfuscation whose goal is to protect global variables, with various modes (encrypt, sign or both), and which ensures that individual obfuscations are performed in an appropriate order. We can also note that cryptographic libraries usually provide a method to specify if we want to encrypt or sign (or both) the target.
Code integrity
Our next step is to protect the code of the function foo against modifications. In order to do so, the next listing adds the CodeIntegrity pass to the obfuscation scheme:
#pragma epona global obfuscate CodeIntegrity(filter="foo")
#pragma epona global obfuscate GlobalArrayEncryption(filter="Gx|Gy")
#pragma epona global obfuscate GlobalArrayIntegrity(filter="Gx|Gy")
Hardening the generated code
The GlobalArrayIntegrity and GlobalArrayEncryption passes generate new functions responsible for checking the integrity and for decrypting the global variables. We would like to harden them further. To that effect, we apply another global obfuscation, ControlFlowGraphFlattening:
#pragma epona global obfuscate ControlFlowGraphFlattening()
#pragma epona global obfuscate CodeIntegrity(filter="foo")
#pragma epona global obfuscate GlobalArrayEncryption(filter="Gx|Gy")
#pragma epona global obfuscate GlobalArrayIntegrity(filter="Gx|Gy")
Even if the generated functions are indeed obfuscated by the ControlFlowGraphFlattening pass, one problem still arises from this scheme: all the other functions of the current module are also transformed. This implies a performance penalty that we may not be ready to pay.
The underlying issue is that our annotation system does not currently allow to target the different code artifacts generated by a previous obfuscation, here the functions generated by GlobalArrayIntegrity and GlobalArrayEncryption [3].
Going further
Beyond the necessity of an extensive reporting all along the obfuscation processing, the previous example has also highlighted the need of being able to build global obfuscating schemes combining several obfuscations in order to achieve an effective protection. The next picture shows the specification of a high level obfuscation pass that combines the passes we described before in the right order and with finer granularity. It would be triggered using the following annotation:
#pragma epona global obfuscation ProtectGlobalVariable(filter="Gx|Gy",
sign=true,
encrypt=true,
check-uses=true,
harden-level=1)
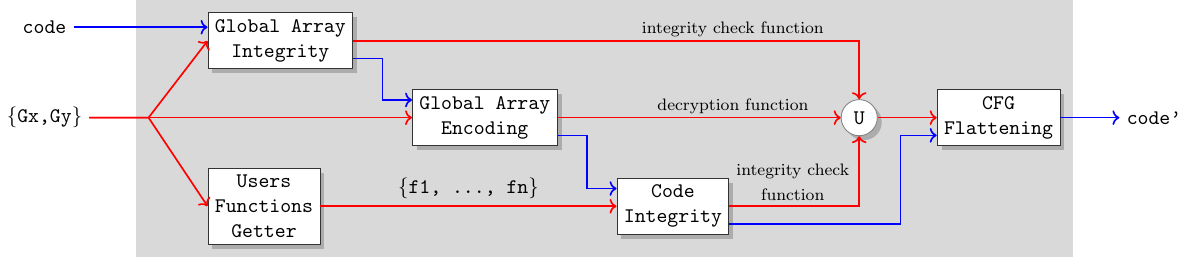
The new pass abstracts away the different building blocks, ensuring they do not interact with each other negatively, thus simplifying the usage of Epona while balancing protection and performance. In particular, notice in the preceding figure how the outputs of the Global Array Integrity, Global Array Encoding and Code Integrity passes are passed on to the final Control Flow Graph Flattening pass, so that only the newly generated integrity checks and decryption functions are actually further obfuscated.
Conclusion
Effectively protecting a program without hampering the performances of the final application is a difficult task which depends on numerous parameters such as the properties of the input code, the capabilities of the obfuscating tool, and the application of the obfuscation passes it offers.
When a protection tool such as Epona can take advantage of guidance from the users, their workflow can be greatly enhanced by providing extensive reports about the transformations actually performed or not performed by the protection passes, and by providing tools to help checking the effectiveness of the protection. Additionally, providing the user with high level protection schemes combining low level obfuscation bricks can promote the protection diversity and help controlling the performance penalty.
To address these matters, we recently integrated in Epona a new framework which will be presented at Spro'19 [4]. Internal obfuscation passes can now issue events (unprocessed, processed, or produced) which are handled by a centralized Pass Listener. The latter dispatches the requests to internal consumers which can issue errors or logs, build reports, annotate the code, fill in code artifacts containers (named Value Views), or provide information for the Epona Report tool which can be used by users to check some obfuscation properties of the generated application.
In addition, the artifact containers can become the inputs of further obfuscation passes. As a consequence, internal passes can be now easily combined to build high level protection schemes, which will be progressively integrated into Epona. So, stay tuned!
Want to know more about application protection?
Register to our webinar on application protection that will be held on September 24th at 11am: http://bit.ly/2Zniu15.
During this session, we will discuss the market of mobile applications as well as security questions it entails. We will go over the available solutions to consider (obfuscation, white box cryptography, secure storage, RASP, app shielding) against reverse-engineering, theft of savoir-faire and/or intellectual property.
Acknowledgments
Many thanks to our colleagues at Quarkslab who proofread this blog post!
| [1] | We could also have used an option to force Epona to crash or emit a warning, in order to find out this kind of issues earlier. However, in real life cases, the amount of emitted warning may be very huge and using Remarks is more appropriate. |
| [2] | Serge Guelton, Adrien Guinet, Pierrick Brunet, Juan Manuel Martinez Caamaño, Fabien Dagnat and Nicolas Szlifierski, Combining Obfuscation and Optimizations in the Real World, 18th {IEEE} International Working Conference on Source Code Analysis and Manipulation, SCAM 2018, Madrid, Spain, September 23-24, 2018, pp. 24-33, https://doi.org/10.1109/SCAM.2018.00010 |
| [3] | Of course, we could target functions already present in the source code. |
| [4] | Pierrick Brunet, Béatrice Creusillet, Adrien Guinet, and Juan Manuel Martinez, Epona and the Obfuscation Paradox: Transparent for Users and Developers, a Pain for Reversers, to be presented at SPRO'19, November 15, 2019, London, United Kingdom. |