Author Jonathan Salwan
Category Program Analysis
Tags concolic execution, binary analysis, Triton, program analysis, 2015
Triton is a Pin-based concolic execution framework which provides some advanced classes to perform DBA.
1 - Abstract
Triton is a Pin-based concolic execution framework which was released on live at SSTIC 2015 and sponsored by Quarkslab. Triton provides components like a taint engine, a dynamic symbolic execution engine, a snapshot engine, translation of x64 instruction into SMT2-LIB, a Z3 interface to solve constraints and Python bindings. Based on these components, you can build tools for automated reverse engineering or vulnerability research.

This blog post will describe Triton under the hood, explain how to use it and show what kind of things we can build with it. Note that this blog post is a kind of reference where each chapter can be read separately.
2 - What kind of things we can build with it
Well, this is a subjective point but you can build everything that requires runtime binaries manipulation. Below is a short list of examples:
Analyze a trace with concrete information
Perform a symbolic execution
Perform a symbolic fuzzing session
Generate and solve path constraints
Gather code coverage
Runtime registers and memory modification
Replay traces directly in memory
Scriptable debugging
Access to Pin functions through a higher level languages (Python bindings)
And probably lots of others things
3 - First view of Pin utilisation through Python bindings
Triton offers the possibility to use some internal functions of Pin. Note that our objective is not to export all Pin's functions through Python bindings, but only a few interesting
Example with a simple syscalls tracer:
01. from triton import *
02.
03. def my_callback_syscall_entry(threadId, std):
04.
05. print '-> Syscall Entry: %s' %(syscallToString(std, getSyscallNumber(std)))
06.
07. if getSyscallNumber(std) == IDREF.SYSCALL.LINUX_64.WRITE:
08. arg0 = getSyscallArgument(std, 0)
09. arg1 = getSyscallArgument(std, 1)
10. arg2 = getSyscallArgument(std, 2)
11. print ' sys_write(%x, %x, %x)' %(arg0, arg1, arg2)
12.
13.
14. def my_callback_syscall_exit(threadId, std):
15. print '<- Syscall return %x' %(getSyscallReturn(std))
16.
17.
18. if __name__ == '__main__':
19.
20. # Start the symbolic analysis from the 'check' function
21. startAnalysisFromSymbol('main')
22.
23. addCallback(my_callback_syscall_entry, IDREF.CALLBACK.SYSCALL_ENTRY)
24. addCallback(my_callback_syscall_exit, IDREF.CALLBACK.SYSCALL_EXIT)
25.
26. # Run the instrumentation - Never returns
27. runProgram()
The output looks like this:
$ ../../../pin -t ./triton.so -script examples/callback_syscall.py -- ./your_binary.elf64
-> Syscall Entry: fstat
<- Syscall return 0
-> Syscall Entry: mmap
<- Syscall return 7fb7f06e1000
-> Syscall Entry: write
sys_write(1, 7fb7f06e1000, 6)
<- Syscall return 6
[...]
As a Pintool in C++, you can add callbacks before or after several cases. At lines 23 and 24, we setup callbacks before and after each system call. At lines 03 and 14 there are our callback handlers which take a threadId and a Standard as integer.
4 - Playing with the taint engine
Triton provides a taint engine. This engine applies an over-proximation but that doesn't affect the precision. In exploit development, what the user wants in reality is knowing if the register is controllable by himself and know what values can hold this register. Answering to this question only with the taint analysis is pretty hard because a lot of instructions have an influence on the value that can hold a register. (Path conditions, arithmetic operations...)
So, our personal reflection about this is: How can we gain time without losing precision?
Symbolic execution offers us the possibility to answer at the question "what value can hold a register?", but applying a symbolic execution and asking a model at each program point if a register is controllable is pretty expensive. Therefore, we use an over-approximation to fix the loss of time and if a register is tainted, we ask a model for the precision.
Example: Imagine this 16-bits register [x-x-x---x-xx-x-x] where x are bits that the user can control and - bits that the user can't control. This state of register is setup like this due to arithmetic operations but may be something else with a different input value. In this case, it's not useful to know what bits are controllable by the user because they will probably change with another input value. So, in this case, using a perfect-approximation or an under-approximation is not useful. What we want is to know what values can hold this register according to the input.
That's why Triton uses symbolic execution for precision and over-approximated tainting to know if we can ask a model to the SMT solver.
4.1 - Using the taint engine through the API
You can predict a taint with the taintRegFromAddr or untaintRegFromAddr functions before running the program. Example:
01. from triton import *
02.
03. if __name__ == '__main__':
04.
05. startAnalysisFromSymbol('check')
06.
07. # Taint the RAX and RBX registers when the address 0x40058e is executed
08. taintRegFromAddr(0x40058e, [IDREF.REG.RAX, IDREF.REG.RBX])
09.
10. # Untaint the RCX register when the address 0x40058e is executed
11. untaintRegFromAddr(0x40058e, [IDREF.REG.RCX])
12.
13. runProgram()
At the line 08, the RAX and RBX registers will be tainted when the instruction 0x40058e will be executed. At line 11, the RCX register will be untaint when the line 0x40058e will be executed. When a register is tainted, Triton will spread the taint according to the instructions' semantic.
You can also taint or untaint registers at runtime inside a callback like this:
01. def cbeforeSymProc(instruction):
02.
03. if instruction.address == 0x40058b: # 0x40058b: movzx eax, byte ptr [rax]
04. rax = getRegValue(IDREF.REG.RAX)
05. taintMem(rax)
06.
07. if __name__ == '__main__':
08.
09. # Start the symbolic analysis from the 'check' function
10. startAnalysisFromSymbol('check')
11.
12. addCallback(cbeforeSymProc, IDREF.CALLBACK.BEFORE_SYMPROC)
13.
14. # Run the instrumentation - Never returns
15. runProgram()
At line 04, we get the content of the RAX register and taint the address. According to the API, we can taint and untaint registers and memory using taintReg(), untaintReg(), taintMem() and untaintMem() functions, and check if a register or memory is tainted with the isRegTainted() and isMemTainted() functions.
All information's modification for the taint and the symbolic engines must be done inside a BEFORE_SYMPROC callback.
5 - Playing with the symbolic engine
The symbolic engine offers the possibility to build symbolic expressions using concrete information and symbolic variables. The user can know at each program point what values can hold a register or part of the memory. All expressions are on SMT2-LIB SSA form.
Below is an example of the add rax, rdx instruction.
Instruction: add rax, rdx
Expressions: #41 = (bvadd ((_ extract 63 0) #40) ((_ extract 63 0) #39))
#42 = (ite (= (_ bv16 64) (bvand (_ bv16 64) (bvxor #41 (bvxor
((_ extract 63 0) #40) ((_ extract 63 0) #39))))) (_ bv1 1)
(_ bv0 1)) ; Adjust flag
#43 = (ite (bvult #41 ((_ extract 63 0) #40)) (_ bv1 1) (_ bv0 1)) ; Carry flag
#44 = (ite (= ((_ extract 63 63) (bvand (bvxor ((_ extract 63 0) #40)
(bvnot ((_ extract 63 0) #39))) (bvxor ((_ extract 63 0) #40) #41)))
(_ bv1 1)) (_ bv1 1) (_ bv0 1)) ; Overflow flag
#45 = (ite (= (parity_flag ((_ extract 7 0) #41)) (_ bv0 1)) (_ bv1 1)
(_ bv0 1)) ; Parity flag
#46 = (ite (= ((_ extract 63 63) #41) (_ bv1 1)) (_ bv1 1)
(_ bv0 1)) ; Sign flag
#47 = (ite (= #41 (_ bv0 64)) (_ bv1 1) (_ bv0 1)) ; Zero flag
As all expressions in Triton are in SSA form, id #41 is the new expression describing the RAX register, id #40 is the previous expression for RAX and id #39 is the previous expression for RDX.
An Instruction can contain several expressions (SymbolicElement). For example, the previous add rax, rdx instruction contains 7 expressions: 1 ADD semantic and 6 flags (AF, CF, OF, PF, SF and ZF) semantics where each flag is stored in a new SymbolicElement class.
Triton deals with 64-bits registers (and 128-bits for SSE). This means that it uses the concat and extract functions when operations are performed on subregister.
Example:
.1: mov al, 0xff -> #193 = (concat ((_ extract 63 8) #191) (_ bv255 8))
.2: movsx eax, al -> #195 = ((_ zero_extend 32) ((_ sign_extend 24) ((_ extract 7 0) #193)))
On the line 1, a new 64bit-vector is created with the concatenation of rax[63..8] and the concretization of the 0xff value. On the line 2, according to the AMD64 behavior, if a 32-bit register is written, the CPU clears the 32-bit MSB of the corresponding register. First we apply a sign extension from al to eax, then a zero extension from eax to rax.
5.1 - Use the symbolic engine through the API
At each callback, an Instruction class is send as handler argument. This class contains a list of symbolic elements. Then it's easy to build a tool which displays the symbolic trace:
01. from triton import *
02.
03. def my_callback_after(instruction):
04. print '%#x: %s' %(instruction.address, instruction.assembly)
05. for se in instruction.symbolicElements:
06. print '\t -> %s %s' %(se.expression,
(('; ' + se.comment)
if se.comment is not None
else ''))
07. print
08.
09. if __name__ == '__main__':
10. startAnalysisFromSymbol('check')
11. addCallback(my_callback_after, IDREF.CALLBACK.AFTER)
12. runProgram()
Output will look like this:
[...]
0x4005a5: add rax, rdx
-> #60 = (bvadd ((_ extract 63 0) #58) ((_ extract 63 0) #54))
-> #61 = (ite (= (_ bv16 64) (bvand (_ bv16 64) (bvxor #60
(bvxor ((_ extract 63 0) #58) ((_ extract 63 0) #54)))))
(_ bv1 1) (_ bv0 1)) ; Adjust flag
-> #62 = (ite (bvult #60 ((_ extract 63 0) #58)) (_ bv1 1)
(_ bv0 1)) ; Carry flag
-> #63 = (ite (= ((_ extract 63 63) (bvand (bvxor ((_ extract 63 0)
#58) (bvnot ((_ extract 63 0) #54))) (bvxor ((_ extract 63 0)
#58) #60))) (_ bv1 1)) (_ bv1 1) (_ bv0 1)) ; Overflow flag
-> #64 = (ite (= (parity_flag ((_ extract 7 0) #60)) (_ bv0 1))
(_ bv1 1) (_ bv0 1)) ; Parity flag
-> #65 = (ite (= ((_ extract 63 63) #60) (_ bv1 1)) (_ bv1 1)
(_ bv0 1)) ; Sign flag
-> #66 = (ite (= #60 (_ bv0 64)) (_ bv1 1) (_ bv0 1)) ; Zero flag
-> #67 = (_ bv4195752 64) ; RIP
0x4005a8: movzx eax, byte ptr [rax]
-> #68 = ((_ zero_extend 24) (_ bv49 8))
-> #69 = (_ bv4195755 64) ; RIP
0x4005ab: movsx eax, al
-> #70 = ((_ sign_extend 24) ((_ extract 7 0) #68))
-> #71 = (_ bv4195758 64) ; RIP
0x4005ae: cmp ecx, eax
-> #72 = (bvsub ((_ extract 31 0) #52) ((_ extract 31 0) #70))
-> #73 = (ite (= (_ bv16 32) (bvand (_ bv16 32) (bvxor #72 (bvxor
((_ extract 31 0) #52) ((_ extract 31 0) #70))))) (_ bv1 1)
(_ bv0 1)) ; Adjust flag
-> #74 = (ite (bvult ((_ extract 31 0) #52) ((_ extract 31 0)
#70)) (_ bv1 1) (_ bv0 1)) ; Carry flag
-> #75 = (ite (= ((_ extract 31 31) (bvand (bvxor ((_ extract 31 0)
#52) ((_ extract 31 0) #70)) (bvxor ((_ extract 31 0) #52)
#72))) (_ bv1 1)) (_ bv1 1) (_ bv0 1)) ; Overflow flag
-> #76 = (ite (= (parity_flag ((_ extract 7 0) #72)) (_ bv0 1))
(_ bv1 1) (_ bv0 1)) ; Parity flag
-> #77 = (ite (= ((_ extract 31 31) #72) (_ bv1 1)) (_ bv1 1)
(_ bv0 1)) ; Sign flag
-> #78 = (ite (= #72 (_ bv0 32)) (_ bv1 1) (_ bv0 1)) ; Zero flag
-> #79 = (_ bv4195760 64) ; RIP
0x4005b0: jz 0x4005b9
-> #80 = (ite (= #78 (_ bv1 1)) (_ bv4195769 64) (_ bv4195762 64)) ; RIP
0x4005b2: mov eax, 0x1
-> #81 = (_ bv1 32)
-> #82 = (_ bv4195767 64) ; RIP
[...]
According to the API you can build symbolic variable at each program point with the convertExprToSymVar() function, like this:
01. def callback_after(instruction):
02. # 0x400572: movzx esi,BYTE PTR [rax]
03. # RAX points on the user password
04. if instruction.address == 0x400572:
05. rsiId = getRegSymbolicID(IDREF.REG.RSI)
06. convertExprToSymVar(rsiId, 8)
At the line 6, Triton converts the current RSI expression to a 8-bits symbolic variable. Triton's Python API defines the getModel() function to send a request and fetch a list of solution for each variable of the formula. If the returned list is empty, it means that the SMT solver failed to find any solution. The reason must be that there is either no solution for the formula (UNSAT) or the SMT solver reached its limit (UNKNOW). Otherwise, a dictionary of model(s) is send to the user where each entry is a valid value of a symbolic variable.
{SymVar_0: 97, SymVar_1: 123, SymVar_2: 90}
5.2 - Symbolic execution use case on a hash routine
To demonstrate an use case of the symbolic engine, we will build a dumb hash routine. The following code checks if the checksum of the user password is equal to 0xad6d (H(p) == 0xad6d). There is probably a lot of collisions and this is what we are looking for with Triton. The expected password is elite but we will try to find something else.
01. char *serial = "\x31\x3e\x3d\x26\x31";
02.
03. int check(char *ptr)
04. {
05. int i;
06. int hash = 0xABCD;
07.
08. for (i = 0; ptr[i]; i++)
09. hash += ptr[i] ^ serial[i % 5];
10.
11. return hash;
12. }
13.
14. int main(int ac, char **av)
15. {
16. int ret;
17.
18. if (ac != 2)
19. return -1;
20.
21. ret = check(av[1]);
22. if (ret == 0xad6d)
23. printf("Win\n");
24. else
25. printf("loose\n");
26.
27. return ret;
28. }
Once the above code is compiled, lines 08, 09 and 11 look like this:
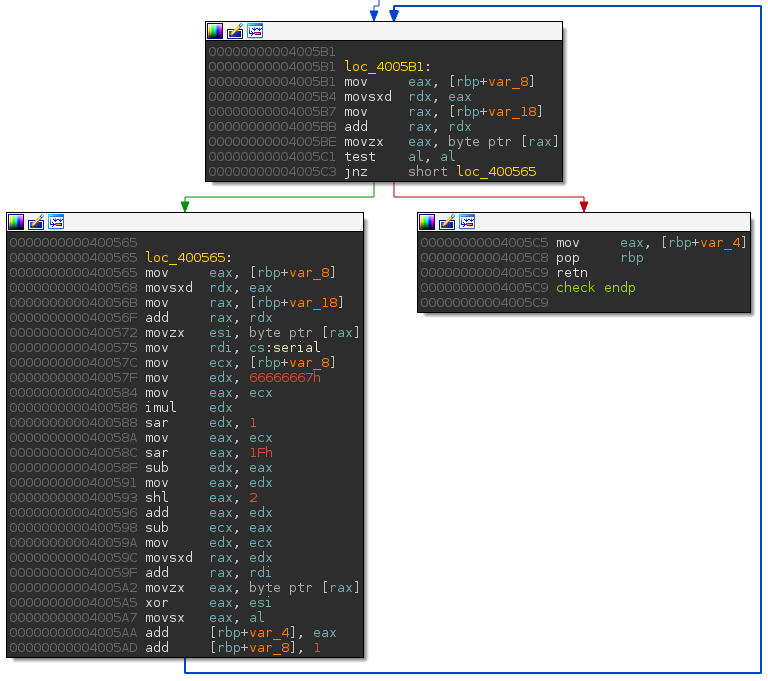
We will setup a new symbolic variable at each loop round on the 0x400572: movzx esi, BYTE PTR [rax] instruction. Then, we will apply an assert(hash == 0xad6d) on the return function (0x4005c5: return hash;) and ask to the SMT solver a valid model.
01. def cafter(instruction):
02.
03. if instruction.address == 0x400572:
04. rsiId = getRegSymbolicID(IDREF.REG.RSI)
05. convertExprToSymVar(rsiId, 8)
06.
07. if instruction.address == 0x4005c5:
08. raxId = getRegSymbolicID(IDREF.REG.RAX)
09. raxExpr = getBacktrackedSymExpr(raxId)
10.
11. # (assert (= rax 0xad6d)
12. expr = smt2lib.smtAssert(smt2lib.equal(raxExpr, smt2lib.bv(0xad6d, 64)))
13. print getModel(expr)
14.
15. if __name__ == '__main__':
16.
17. startAnalysisFromSymbol('check')
18. addCallback(cafter, IDREF.CALLBACK.AFTER)
19. runProgram()
As you can see, the Triton code is really short and Triton has found a collision:
$ triton ./crackme_hash_collision.py ./samples/crackmes/crackme_hash aaaa
{'SymVar_1': 77, 'SymVar_0': 68, 'SymVar_3': 89, 'SymVar_2': 4}
loose
$
Now, if we want only printable characters, we just have to insert anothers assert.
01. def cafter(instruction):
...
07. if instruction.address == 0x4005c5:
08. print '[+] Please wait, computing in progress...'
09. raxId = getRegSymbolicID(IDREF.REG.RAX)
10. raxExpr = getBacktrackedSymExpr(raxId)
11. expr = str()
12.
13. # We want printable characters
14. # (assert (bvsgt SymVar_0 96)
15. # (assert (bvslt SymVar_0 123)
16. expr += smt2lib.smtAssert(smt2lib.bvugt('SymVar_0', smt2lib.bv(96, 64)))
17. expr += smt2lib.smtAssert(smt2lib.bvult('SymVar_0', smt2lib.bv(123, 64)))
18.
19. # (assert (bvsgt SymVar_1 96)
20. # (assert (bvslt SymVar_1 123)
21. expr += smt2lib.smtAssert(smt2lib.bvugt('SymVar_1', smt2lib.bv(96, 64)))
22. expr += smt2lib.smtAssert(smt2lib.bvult('SymVar_1', smt2lib.bv(123, 64)))
23.
24. # (assert (bvsgt SymVar_2 96)
25. # (assert (bvslt SymVar_2 123)
26. expr += smt2lib.smtAssert(smt2lib.bvugt('SymVar_2', smt2lib.bv(96, 64)))
27. expr += smt2lib.smtAssert(smt2lib.bvult('SymVar_2', smt2lib.bv(123, 64)))
28.
29. # (assert (bvsgt SymVar_3 96)
30. # (assert (bvslt SymVar_3 123)
31. expr += smt2lib.smtAssert(smt2lib.bvugt('SymVar_3', smt2lib.bv(96, 64)))
32. expr += smt2lib.smtAssert(smt2lib.bvult('SymVar_3', smt2lib.bv(123, 64)))
33.
34. # (assert (bvsgt SymVar_4 96)
35. # (assert (bvslt SymVar_4 123)
36. expr += smt2lib.smtAssert(smt2lib.bvugt('SymVar_4', smt2lib.bv(96, 64)))
37. expr += smt2lib.smtAssert(smt2lib.bvult('SymVar_4', smt2lib.bv(123, 64)))
38.
39. # We want the collision
40. # (assert (= rax 0xad6d)
41. expr += smt2lib.smtAssert(smt2lib.equal(raxExpr, smt2lib.bv(0xad6d, 64)))
42. print {k: "0x%x, '%c'" % (v, v) for k, v in getModel(expr).items()}
Below, Triton has found a collision with printable characters.
$ triton ./crackme_hash_collision.py ./samples/crackmes/crackme_hash aaaaa
[+] Please wait, computing in progress...
{
'SymVar_0': "0x6c, 'l'",
'SymVar_1': "0x72, 'r'",
'SymVar_2': "0x64, 'd'",
'SymVar_3': "0x78, 'x'",
'SymVar_4': "0x71, 'q'"
}
loose
As you can see, play with the dynamic symbolic execution (DSE) engine is pretty easy and fun via the Python bindings :).
6 - Playing with the snapshot engine
Triton allows the user to replay a trace. During the execution, it is possible to take a snapshot of the registers and memory states. Then, at each program point, it is possible to restore the previous snapshot.
Example: Imagine a trace with a LOAD value, this value is controllable by the user. Then, some operations are applied to this value and at the end the value is verified with a constant. At the compare instruction the formula of the operation applied to the value is built: by assigning a symbolic variable to the input value, it is possible to solve the formula (if it is satisfiable). So, it will be useful to directly inject the model returned by the solver in memory instead of re-run the program.

As taking a snapshot of the full memory is not really possible, Triton saves all bytes before modification of the memory (STORE access) in a list (ML) where each item is a tuple (addr, byte).
When the snapshot must be restored, this list is traversed reversely and all modifications are re-injected in memory like this:
for addr, byte in ML:
*addr = byte
Please note that Triton cannot restore files description, kernel objects, close files which were opened, restore disc I/O, network traffic and so one... That's why we suggest to use the snapshot engine only on short distances.
7 - Conclusion
With Triton you can use some Pin functions and some advanced classes which will allow you to perform symbolic execution, taint analysis, snapshot and translate instructions into SMT2-LIB representation. The wiki describes Triton under the hood. As Triton is a young project, please don't blame us if it is not yet reliable. Open issues or pull requests are always better than troll =).